0. 서문
한 반 년 전 쯤에 정성스러운 뻘글을 하나 썼었다.
사족으로 붙은 헛소리가 너무 심해서 지금은 내렸는데, 요지는 이 정도였다 :
- R이고 파이썬이고 코딩을 칠 수 있는 것 자체가 중요한 게 아니다, 요즘 GPT한테 물어보면 다 짜준다 (물론 질문을 똑바로 넣지 않으면 이상한 라인을 뱉긴 하지만)
- 통계학은 만물상이 아니다. 어렵게 어렵게 통계 공부했다고 바로 실전에서 써먹을 수 있는 게 아니라, 내 필드에서 쓰는 프레임웍을 이해할 수 있는 베이스 정도의 느낌이다.
여기에 뇌절만 안했으면 글이 아마 살아 있었을 텐데.
아무튼 저 두 문장은 아직도 변함없는 생각이다. 물론 처리가 단순한 데이터들만을 다루는 실험실 같은 경우는 간단한 통계만으로 결과를 뽑아낼 수 있기야 하겠지만, 일반적인 경우에는 그렇지 않을거다.
일례로, 내가 직접 본 적은 없지만 PRISM이라는 툴을 쓰는 랩실이 상당히 많은 걸로 알고 있다. 프리즘에서 사용하는 통계량들이 모두 단순한 통계량이냐, 아니다. 통계학과 학부 전공생들은 프리즘에서 지원하는 모든 통계량들을 모두 달달달 알고 있느냐, 아니다. 다만 전공자들은 수식이나 유도 과정을 읽고서 훨씬 쉽게 그 의미를 받아들일 수 있는 사람들이다.
요지가 뭐냐. 다가오는 2024 수능 기준으로는 선택과목이지만, 수능 수학을 대비해서 미적분을 공부한다고 치자.
교과서에서 유도하는 수식은 아마 지수함수나 삼각함수의 미분법 정도였을 것이다.
\( f(x) =4e^{2x} - 3\cos x \) 라고 함수를 딱 특정해 두고 미분하는 전개식을 풀어 써준 게 아니었지만, 수능에서 저 함수를 미분하라는 문제가 나왔을 때 우리는 쉽게 풀 수 있었을거다. 왜냐면, 우리가 그렇게 공부했기 때문이다.
통계도 마찬가지여야 한다.
논문을 뒤져보면, 데이터를 분석에 쓰는 수많은 프레임웍이 있다. 아니, 프레임웍까지 가지 않더라도 Jackknife와 같은 수많은 통계량이 있다 (처음 들어봤어도 그런 게 있다고 치자).
그들은 지수함수나 삼각함수 정도 레벨의 개념이라기 보다는 앞서 예시로 들었던 \(f(x)\) 정도의 레벨로 보는 게 맞을 것 같다. '평균' 등의 요소를 이용해서 쓴, 주어진 상황과 조건에서 퍼포먼스가 잘 나오는 수식이다.
더 쉽게 말해서, '필요하면 찾는' 친구들이다. 당연히 교양 지식으로 알아야만 하는 친구들이 아니라는 말이다.
그리고 그 근간에 회귀 분석과 같은, 기초 통계학 레벨에서부터 다루는 주제들이 있다.
얘네를 공부하는 이유가 그것이다. 지수함수와 삼각함수의 미분법을 잘 알아야 저 \(f(x)\)를 미분할 수 있는 것과 같다.
당장 이거 하나만을 실전에서 바로 써먹으려고만 공부하는 게 아니라는 의미다.
그리고 그런 관점에서 보면, 단순 선형 회귀(Simple linear regression) 부터가 제대로 이해하기에 생각보다 만만치 않은 놈이라는 걸 알게 된다. 당연하다. 기초 통계학에서 다룬다고 쉬운 내용이라는 건 아니다.
그래서 여기서는 수식보다는 직관적인 해석 위주로 소개하려고 한다.
기초적인 노테이션이나 선형 회귀의 수학적 설명은
https://www.tandfonline.com/doi/full/10.1080/17457300.2018.1426702
이쪽을 참고. 라이센스가 걸려있긴 하지만 아마 학교 네트워크 등으로 열릴 거다. 세 페이지 짜리 짧은 글에다 변수 하나짜리만 다루기 때문에 쉬워서 종종 잘 써먹고 있다.
링크가 안 열리면 그냥 구글링해서 나오는 한국어 블로그들 같은 걸 봐도 좋다. 어차피 기본적으로 아래서 할 이야기는 이 노트에는 없는 내용이긴 하다.
1. 선형 회귀의 의미
간단히, 선형 모델은 다음과 같이 쓴다 (수식의 유도는 레퍼런스를 참고하거나 구글링 해보자) :
$$ y = \mathbf{X\beta} + \epsilon $$
(여기서 y와 베타, 엡실론은 벡터고 X는 매트릭스다)
즉 우리는 어떤 결과 (response variable ; 반응 변수) Y를 할 수 있을 만큼 실험 조건 (predictor ; 독립 변수) X의 선형 결합(linear combinatoin ; X들의 합으로 표현된 다항식)으로 최대한 설명하고, 설명하지 못하는 부분은 실험적인 오차나 어쩔 수 없이 발생하는 오류(error term ; \(\epsilon\))로 두는 것이다.
우리의 n=20짜리 실험 결과 데이터 Y가 아래와 같이 있다고 하자 :
# 난수로 뽑았다. 아래에 이 데이터를 생성한 코드도 첨부하겠다.
Y
#> [1] 35.08132 38.97359 36.26591 41.69685 41.53767 32.56127 36.92310 40.05056 35.78671
#> [10] 34.47990 40.79967 36.13002 36.89172 39.48622 32.28644 38.83073 33.57491 30.38676
#> [19] 34.69553 39.92492
더 직관적으로는
ggplot(df, aes(position, Y)) + geom_point(size = 3, alpha = .5)

우리가 하고 싶은 건 이 Y가 왜 저 값이 나왔는지 설명하는 것이다.
그런데 이대로 놓고 보면 당최 뭔지를 알 수가 없다. 그래서 적절한 실험 조건 변수 X를 가져와 보았다.
이때 X는 온도나 습도 혹은 시약의 뭐시기(?) 같은, 우리가 실험하면서 기록해 놓은 값이다.
# 이 X도 역시 랜덤으로 뽑았다.
X
#> [1] 2.8757752 7.8830514 4.0897692 8.8301740 9.4046728 0.4555650 5.2810549 8.9241904
#> [9] 5.5143501 4.5661474 9.5683335 4.5333416 6.7757064 5.7263340 1.0292468 8.9982497
#> [17] 2.4608773 0.4205953 3.2792072 9.5450365
혹시 이 X가 Y에 영향을 미치지 않았을까, 이미 알고 있는 X 값으로 Y를 설명하면 좋을 것 같다.
그래서 그려보면 :
ggplot(df, aes(X, Y)) + geom_point(size = 3, alpha = .5)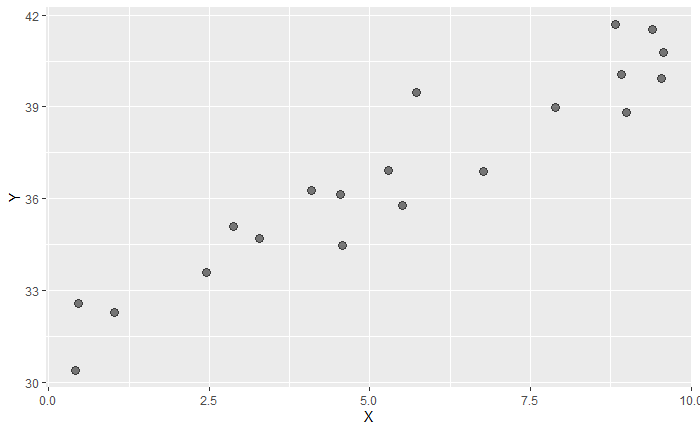
여기서 우리가 잡은 설명변수(explanatory variable), 혹은 프리딕터(predictor)인 X의 의미를 이해할 수 있다.
원래는 1차원 데이터에, 랜덤하게 보였던 Y를, 이미 알고 있는 X를 내가 내 맘대로 골라서 그에 맞게 Y의 점들을 좌우로 펼쳐서 그려보니 우상향하는 것 같은 그림이 그려졌다.
이런 경향을 보고 '내가 고른 X가 Y에 영향이 있을 수 있겠다' 와 같은 이야기를 하는 것이 회귀 분석이다.
만약 옆 자리에서 똑같은 Y를 분석하는 다른 친구가, 내가 고른 X 대신 다른 변수 X3을 프리딕터로 골랐다고 해보자.
# 변수 이름이 X3인 이유는 없다. 그냥 근갑다 하자.
X3
#> [1] 1.4280002 4.1454634 4.1372433 3.6884545 1.5244475 1.3880606 2.3303410 4.6596245
#> [9] 2.6597264 8.5782772 0.4583117 4.4220007 7.9892485 1.2189926 5.6094798 2.0653139
#> [17] 1.2753165 7.5330786 8.9504536 3.7446278
ggplot(df, aes(X3, Y)) + geom_point(size = 3, alpha = .5)
Y를 X3에 따라서 쭉 펼쳐봐도 경향성이 보이지 않는다. 아까 내가 고른 X에 비해서, 친구가 고른 X3은 Y의 값을 결정하는 데 영향이 없는 것 같다. 어깨 두어번 토닥토닥 해주고, 앞으로 Y를 분석할 때 X3는 생각하지 않아도 될 것 같다.
회귀 분석으로 X가 Y에 영향을 줬음을 알 수 있었듯, X3가 Y에 영향을 주지 않았음을 판단하기도 한다.
그럼 그걸 어떻게 판단하는가.
생각보다 엄청나게 중요한 문제다. 사실 X3 그림, 마음의 눈으로 보면 저것도 우하향하는 것처럼 보이지 않는가.
그래서 이런 결정을 후회없이 내리기 위해선 누구나 동의할 수 있을 정량적인 증거가 필요하다.
그리고 그게, 우리가 기초 통계학에서 배웠던 p-value다. 그 p-value를 계산하기 위해서 하는 게, 세트로 같이 배웠던 t-test니 ANOVA니 하는 것들이다.
감사하게도 똑똑하신 분들께서 이 계산을 간단하게 할 수 있는 툴을 만들어 주셨다.
# Y를 X에 대해 선형 회귀.
fit = lm(Y~X, data = df) ; summary(fit)
#> Call:
#> lm(formula = Y ~ X, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.43652 -0.92143 -0.06831 0.76440 2.45236
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 31.37498 0.49674 63.16 < 2e-16 ***
#> X 0.98822 0.07886 12.53 2.51e-10 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 1.078 on 18 degrees of freedom
#> Multiple R-squared: 0.8972, Adjusted R-squared: 0.8914
#> F-statistic: 157 on 1 and 18 DF, p-value: 2.506e-10# 그림.
coef = fit$coefficients
ggplot(df, aes(X, Y)) +
geom_point(size = 3, alpha = .5) +
geom_abline(slope = coef[2], intercept = coef[1], col = 'red4')
※ 각 R 함수에 대한 자세한 description은 구글링하거나 혹은 R console에 ` ?lm ` 등을 입력하면 볼 수 있다.
위쪽 코드블럭의 summary fit result를 보면 다양한 정보가 있다.
먼저 직선 \( Y = \beta_0 + \beta_1 X \) 에 대해, coefficients의 Pr (여기가 p-value다) 값은 그 베타 값이 유의한지를 보여준다. 보통 한 눈에는 별(*)의 수로 판단해도 좋다. 위 모델의 경우는 OLS 추정량 (=베타값을 뜻하는 이름이다. 자세한 건 초반에 걸어둔 레퍼런스를 참고하거나 구글링) 이 모두 유의하게 잘 나왔음을 의미한다 (여기서 각 데이터가 가운데 빨간 선으로 모이기 때문에, 이런 방식의 분석을 "회귀 분석" 이라고 한다) .
P-value 옆에 붙어 있는 다른 값, 그러니까 '추정치'나 'std. error', 't value' 등은 이 p-value를 뽑아내기 위해 필요한 정보들이다. 여기서의 베타 값들은 t-test로 검정하니, 매칭 시켜보면서 p-value가 왜 저 값이 나왔는지 따라가 보는 것도 좋겠다.
개별 \(\beta_i\) 값에 대한 t-test
$$ H_0\;:\;\beta_i = 0 \quad vs. \quad H_1\;:\;\mathrm{not}\;H_0\;. $$
그렇다고 이 모델이 좋은 모델이냐, 그건 또 추정량만 보고 단언할 수 없다.
맨 아래쪽의 지표들은 간단히 다음과 같이 이해하면 대충 비슷하다 (자세한 수식이나 정확한 의미는 구글링.) :
- Residual standard error : 대충 각 데이터가 가운데 선으로부터 얼마나 떨어져 있는가, 를 한 숫자로.
- R-sqared : 인풋 변수들과 Y의 correlation 같은 느낌이라고 생각해도 좋고, 1에 가까울수록 우리 모델이 좋은 것이다.
- F-statistic : 우리 모델에 의해 설명되는 부분과 설명하지 않은 부분의 비율 같은 느낌으로 이해해도 좋다. 숫자가 크면 모델에 의해 설명되는 부분이 많은 것이며, p-value도 줄어든다.
이 세 지표는, 위의 coefficients 부분과는 다르게 모델을 통째로 놓고 봤을 때를 평가하는 것이다. 각 베타 값들 옆에 별이 많이 떠 있다고 해서, 이 지표들이 항상 최선을 나타내는 건 아니다 (아래의 2절에 적어 두겠다) .
모델에 대한 F-test
$$ H_0\;:\;\beta_0 =\beta_1 =\cdots=\beta_p = 0 \quad vs. \quad H_1\;:\;\mathrm{not}\;H_0\;. $$
그래서 회귀 분석의 모델을 결정할 때는 이 모든 지표들을 종합적으로 잘 봐줘야 한다.
그럼 X3으로 모델을 fitting 했을 때와 이 결과를 비교해보자.
fit2 = lm(Y~X3, data = df) ; summary(fit2)
#> Call:
#> lm(formula = Y ~ X3, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -5.4387 -1.9345 0.0715 2.2971 4.7833
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 38.6556 1.2583 30.721 <2e-16 ***
#> X3 -0.4723 0.2697 -1.751 0.0969 .
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 3.106 on 18 degrees of freedom
#> Multiple R-squared: 0.1456, Adjusted R-squared: 0.0981
#> F-statistic: 3.067 on 1 and 18 DF, p-value: 0.09694
coef = fit2$coefficients
ggplot(df, aes(X3, Y)) +
geom_point(size = 3, alpha = .5) +
geom_abline(slope = coef[2], intercept = coef[1], col = 'blue')
R-sq 값도 많이 좋지 않고, X3 변수의 베타값이 0.05보다 큰 기각역에 속해 있다. 이를 근거로, 모델 전체도 좋지 않을 뿐더러 X3이 Y에 선형적인 영향은 없다고 볼 수 있다.
그럼 우리는 위의 X만 사용한 모델을 선택하는 게 맞을까?
2. 시행 착오 : 모델의 비교
수학 문제와는 다르게, 회귀 분석은 "분석" 이다. 해석이 중요하다.
실컷 봤던 Y를 다시 들고 와보자. X도, X3도 아닌 새로운 변수 X2에 대해서 관계성을 조사해 보았다 :
X2
#> [1] 10.88954 10.69280 10.64051 10.99427 10.65571 10.70853 10.54407 10.59414 10.28916
#> [10] 10.14711 10.96302 10.90230 10.69071 10.79547 10.02461 10.47780 10.75846 10.21641
#> [19] 10.31818 10.23163
ggplot(df, aes(X2, Y)) + geom_point(size = 3, alpha = .5)

많이 퍼져있긴 한데, 단순히 관계가 없다고 하기엔 뭔가 찝찝한 것 같기도 하다.
회귀 모형을 때려 보자.
fit3 = lm(Y~X2, data = df) ; summary(fit3)
#> Call:
#> lm(formula = Y ~ X2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -4.9565 -1.8050 0.1101 2.0827 4.9384
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -19.321 25.184 -0.767 0.4529
#> X2 5.308 2.380 2.230 0.0387 *
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 2.974 on 18 degrees of freedom
#> Multiple R-squared: 0.2165, Adjusted R-squared: 0.1729
#> F-statistic: 4.973 on 1 and 18 DF, p-value: 0.03872
coef = fit3$coefficients
ggplot(df, aes(X2, Y)) +
geom_point(size = 3, alpha = .5) +
geom_abline(slope = coef[2], intercept = coef[1], col = 'green3')
절편 값이 구리긴 하지만, X2도 Y에 영향이 있다고 하고, 모델 자체의 p-value도 채택역 안에 들어와 있다.
하지만 그럼에도 앞에서 봤던 빨간 선의 모델 (fit 모델) 보다는 설명력이 떨어지는 결과이긴 하다.
그럼 X2 변수를 버리는 게 맞을까?
둘 다 쓰면 안될까? 즉,
$$ Y = \beta_0 + \beta_1 X + \beta_2 X_2 + \epsilon $$
fit4 = lm(Y ~ X + X2, data = df) ; summary(fit4)
#> Call:
#> lm(formula = Y ~ X + X2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.37366 -0.60419 -0.01248 0.57300 1.93929
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 6.24899 7.50900 0.832 0.41683
#> X 0.92509 0.06573 14.073 8.48e-11 ***
#> X2 2.40847 0.71878 3.351 0.00379 **
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.8605 on 17 degrees of freedom
#> Multiple R-squared: 0.9381, Adjusted R-squared: 0.9308
#> F-statistic: 128.7 on 2 and 17 DF, p-value: 5.389e-11
ggplot(df, aes(X, X2, col = Y)) +
geom_point(size = 3)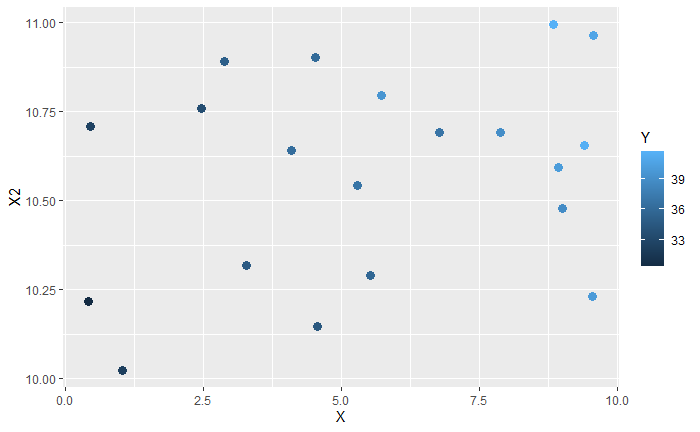
이 결과를 X 혹은 X2 하나씩만 썼을 때의 결과와 비교해 보자.
각 변수들의 설명력도, 모델 전체의 평가 지표도 더욱 좋아졌다 (보통 Intercept는 고려하지 않는다. 실전에서는 데이터를 pre-processing 한 뒤 넣기 때문에 많은 경우 과학적인 의미를 갖고 있지 않다. 중요한 건 X-Y, X2-Y의 관계인 것) .
항을 하나만 더 추가해보자. 혹시 X와 X2가 동시에 커졌을 때, 시너지 효과가 발생한다면? 충분히 그럴 수도 있지 않은가?
$$ Y = \beta_0 + \beta_1 X + \beta_2 X_2 + \beta_3 X \times X_2 + \epsilon $$
fit5 = lm(Y ~ X + X2 + X * X2 , data = df) ; summary(fit5)
#> Call:
#> lm(formula = Y ~ X + X2 + X * X2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.3742 -0.5947 0.0399 0.5731 1.9447
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 11.4864 13.6319 0.843 0.412
#> X -0.1550 2.3225 -0.067 0.948
#> X2 1.9095 1.3006 1.468 0.161
#> X:X2 0.1024 0.2200 0.465 0.648
#>
#> Residual standard error: 0.881 on 16 degrees of freedom
#> Multiple R-squared: 0.9389, Adjusted R-squared: 0.9274
#> F-statistic: 81.94 on 3 and 16 DF, p-value: 6.314e-10
F-통계량도 R-sq도 잘 나오는데 각 베타값들 중 유의한 게 하나도 없다.
즉 앞에서 언급했던 t-test와 F-test의 귀무가설을 생각해 보면,
F-test에 의해 \( H_0\;:\;\beta_0 =\beta_1 =\cdots=\beta_p = 0 \) 는 기각. 다시 말해, 적어도 하나는 의미가 있는 변수임.
t-test에 의해 \( H_0\;:\;\beta_i=0 \)는 모든 i에 대해 기각할 수 없음.
이를 둘 다 고려해보면, X와 X2가 뭔가 모델에 영향이 있긴 있는데 조합이 잘못되었다고 생각해 볼 수 있다.
아, 슬슬 머리가 복잡해진다. 그러니 여기까지만 보자.
실제로 모델을 진단하는 여러가지 수학적인 지표들이 존재하고, 추측할 수 있는 문제 상황들도 꽤나 복잡하며, 모델을 평가하기 위한 알고리즘적 방식도 있다. 이는 한두 줄 정도로 요약할 수 있는 게 아니고 사전 지식도 좀 필요하니 궁금하면 따로 araboza.
여기서 보여주고 싶었던 건, 회귀분석 과정이 정답을 뚝딱 뱉어내는 도구가 아니라는 것, 생각보다 모호해서 시행 착오가 있다는 것이다.
되짚어보자. 우선 변수 X와 X2, X3는 어디서 뚝 떨어진 게 아니라 내가 임의로 잡은 변수다. 가만히 있던 Y를, 내가 내 맘대로 가져온 X들에 대해서 쭉쭉 늘려보고 난 뒤에, 잘 맞는 걸 선택하는 것이다. 혹시 중요한 뭔가를 놓쳤다면 그대로 끝이다. 물론 보통 중요한 변수라면 결과가 좀 흠 싶어서 놓친 게 없는지 되돌아보기도 한다.
다음으로, 모델이 복잡하다고 (즉, 항이 많다고) 해서 모델이 좋아지는 게 아니라는 것이다. 우리는 교호항을 넣은 fit5 모델이 교호항을 넣지 않았던 fit4 모델보다 성능이 떨어진 걸 확인했다.
아무튼 그래서 모델의 선택은 신중해야 한다. 가이드라인은 있겠지만, 변수와 결과의 해석 등을 상회하여 일맥 상통하는 절대적인 바이블은 없다고 보는 게 속이 편하다. 분석은 언제나 상당한 시행착오가 함께한다는 걸 염두에 두자.
# 참고. 회귀식이 잘 나오도록 하는 Y, X, X2, X3의 생성
# 샘플 수가 20개밖에 안돼서 그렇지, `fit4`가 꽤나 잘 맞혀줬다.
X = runif(20, 0, 10); Y = numeric(); X2 = runif(20, 10, 11); X3 = runif(20, 0, 10)
for(i in 1:20){
mu = function(x1, x2) 10 + x1 + 2*x2
Y[i] = rnorm(1, mu(X[i], X2[i]), 1)
}
df = data.frame(X = X, Y = Y, X2 = X2, X3 = X3, position = factor(1)); df
이제 R이든 SAS든 SPSS든 PRISM이든 컴퓨터가 정말 쉽게 계산해준다는 걸 알았으니 신나서 "논문 다 뒤졌다 내가 간다" 할 수 있지만, 그러면 안된다. 이건 또 뭔 소리여.
3. 선형 회귀의 가정(assumption)
예를 들어 n=100인 response variable B가 연속적인 숫자가 아닌, '예' 와 '아니오' 두 가지로만 이루어져있다고 해보자.
ggplot(df) + geom_bar(aes(factor(B)), width = .3)
적당한 X에 대해서, 위에서처럼 B를 양쪽으로 쭉 잡아 늘려보면 아래처럼 된다 :
ggplot(df, aes(X, B)) + geom_point(size = 3, alpha = .5)
찜찜하긴 하지만 뭔가 경향성이 보이는 것 같긴 하다. 그래서 방금 알게 된 선형 회귀로 피팅해보면
fit6 = lm(B ~ X, data = df); summary(fit6)
#> Call:
#> lm(formula = B ~ X, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.69741 -0.19030 -0.04261 0.19456 0.76982
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.571921 0.032299 17.71 <2e-16 ***
#> X 0.066646 0.005695 11.70 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.323 on 98 degrees of freedom
#> Multiple R-squared: 0.5829, Adjusted R-squared: 0.5786
#> F-statistic: 136.9 on 1 and 98 DF, p-value: < 2.2e-16
P-value 들이 기가 막히다. 너무 잘 나왔다.
그래서 얘를 써보려고 그림으로 그려보면,

뭔가 이상하다.
실제로 선형 회귀의 의미상, 저 선은 랜덤 효과가 없을 때의 B의 기댓값이다. 그런데 우리는 B가 0 혹은 1, 둘 중 하나로만 나온다는 걸 알고 있다. 랜덤한 효과가 없다고 한들 절대로 저 선에 떨어질 수는 없다는 뜻이다.
다시 말해서, 저 선을 적당히 뚝 잘라서 0.5보다 작은 놈들은 0으로, 0.5보다 큰 놈들은 1로 보내기에는 애초에 회귀분석의 의미와 달라져 버린다는 거다. 그러려면 직선이 실제 데이터 값이 아니라 확률을 의미했어야 한다. 직선의 함숫값이 0.6이라는게, 1이 나올 확률이 0.6을 뜻하는 게 아니라는 뜻이다.
한 마디로, 애초부터 선형 회귀가 안되는 상황이다. 그럼에도 R은 너무나도 매력적인 결과를 뱉어낸다.
그럼 궁금해진다. 언제 선형 회귀를 쓸 수 있고, 언제 쓸 수 없는가?
이를 결정하는 것이 선형 회귀의 가정(assumption) 이고, 이런 맥락이기 때문에 굉장히 굉장히 중요하다.
자세한 서술은 다양한 경로로 쉽게 접할 수 있기 때문에 간단히 소개만 하겠다.
1. 반응 변수 Y는 설명 변수 X들의 선형 결합으로 표현된다. 즉, 모델에 뜬금없이 지수함수나 삼각함수 같은 게 튀어나오거나 하면 좀 곤란하다 (선형성).
2. 설명 변수 X들은 서로 독립이다. 얘들이 독립이 아니면 결과가 좀 이상해진다 (독립성. 이게 깨진 상황을 '다중공선성; multicollinearity' 라고 부른다).
3. 반응 변수 Y만이 확률 변수이다. 확률 변수 Y는, 특정한 X에 대해서 정규 분포 \( N(\mathbf{X\beta}, \sigma^2) \) 를 따른다 (정규성. 이 가정 때문에, error term \(\epsilon\) 이 정규 분포를 따른다).
4. X가 달라져도 Y의 분산은 동일하다 (등분산성 ; homoscedasticity) .
4. GLM과 머신러닝에서의 선형 회귀
선형 회귀의 가정을 간단히 요약하면 "균일하게 잘 퍼져 있는 정규분포" 이다.
고등학교 확률과 통계 (혹은 기초 통계학) 에서 배웠던 내용을 떠올려보자. 정규분포에서 가능한 x값은 실수 전체이다.
즉 평균이 0이고 분산이 1인 정규분포를 따르는 확률 변수도, 굉장히 낮은 확률로 \( -10^{10000000000} \) 와 같은 말도 안되는 작은(혹은 큰) 수가 나올 수 있다는 뜻이다 (이게 잘 이해가 안된다면, 이항분포에서는 정의상 0.5라는 수가 뽑힐 수 없다는 걸 생각해보자) .
앞서 봤던 관측 데이터 B를, 선형 회귀를 돌리면 안되는 이유가 여기에 있다. B는 정규 분포가 아니기 때문에 선형 회귀를 돌리면 안된다. 마찬가지로, 어떤 일이 일어날 "횟수(count 등, 예를 들어 세포 수)" 역시도 단순하게 선형 회귀를 돌리면 안된다. 횟수는 0 아래로 내려갈 수가 없기 때문이다 (즉, 횟수가 0보다 작게 나올 확률은 0이다).
그럼 얘들은 회귀 분석을 못하는 걸까? 그랬다면 회귀 분석론은 진즉에 사장되었을 것이다.
아이디어는 간단하다. 확률 변수를 잘 만져서 확률이 0이 아닌 구간이 실수 전체가 되도록 만든 다음에, 선형 회귀를 하면 된다.
뭔 소리여. B를 다시 보자.

이 데이터에서 X값이 커질 수록 답변은 '예' 쪽에 몰려 있다. 즉, X에 따라 '예' 라고 대답할 확률이 변한다고 해석해보는 거다.
그러면 확률의 공리 상 확률은 0과 1 사이의 값이다. 쉽게 말해서, 0보다 작거나 1보다 큰 확률, 본 적 없잖아.
"0 or 1" 에서 "0과 1 사이의 수" 로 확장되었다.
다음 할 일은, 이 0과 1 사이의 수를 실수 전체로 확장하는 일이다. 주어진 X에서의 확률을 \(\pi(X)\) 라고 할 때,
$$ \frac{\pi(X)}{1-\pi(X)} $$
라는 식을 생각해보자 (유도 없이, 그리고 쟤가 뭘 의미하는지와 같은 복잡한 내용도 빼고, 그냥 하늘에서 뚝 떨어졌다고 치자). 잘 생각해보면 저녀석은 확률 값을 넣으면 0에서 양의 무한대 사이의 어떤 숫자든 뱉어낼 수 있는 연속 함수가 된다.

"0과 1 사이의 수" 에서 "0보다 같거나 큰 실수" 범위로 확장되었다.
비슷하게, 이 친구를 음의 무한대부터 양의 무한대까지 쭉 늘려주면, 드디어 선형 회귀를 적용할 수 있겠다.
이를 위해 위의 식에 로그를 취해주자. 그러면 이제 적당한 확률 값을 넣었을 때, 실수 전체 범위에서 아무거나 하나를 딱 뱉어내는 함수가 된다.
$$ \log\frac{\pi(X)}{1-\pi(X)} $$
이 함수를 "로짓 함수(logit function)" 이라고 부른다. 이렇게 바꿔준 뒤 여기에 선형 회귀를 먹여주면, 우리는 \(\pi(X)\)에 대한 값을 추정할 수 있다 (바로 와닿지는 않더라도, 느낌만 보자. 처음 보면 당연히 헷갈리는 게 정상이다).
이걸 '로지스틱 회귀 분석(logistic regression)' 이라고 한다. 좌변에 로짓 함수가 들어가 있어서.
그래서 우리는 데이터 B에 대해서 아래와 같은 모델을 생각해 볼 수 있다.
$$ \log\frac{\pi(X)}{1-\pi(X)} = \beta_0 + \beta_1 X + \epsilon$$
# 로지스틱 회귀.
fit7 = glm(B ~ X, family = 'binomial', data = df); summary(fit7)
#> Call:
#> glm(formula = B ~ X, family = "binomial", data = df)
#>
#> Deviance Residuals:
#> Min 1Q Median 3Q Max
#> -2.02656 -0.34699 0.09579 0.33849 2.08042
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 0.8531 0.3739 2.281 0.0225 *
#> X 0.5646 0.1126 5.016 5.28e-07 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> (Dispersion parameter for binomial family taken to be 1)
#>
#> Null deviance: 136.663 on 99 degrees of freedom
#> Residual deviance: 58.805 on 98 degrees of freedom
#> AIC: 62.805
#>
#> Number of Fisher Scoring iterations: 6
여기서의 곡선 의미는 선형 회귀와는 조금 다르다.
위의 선형 회귀에서 함숫값은 실제 데이터의 기댓값이다. 좌변에 Y가 그대로 들어왔으니까 당연하다.
$$ Y = \beta_0 + \beta_1 X + \beta_2 X_2 + \epsilon $$
그런데 로지스틱 함수에서 좌변은 확률의 odds ratio(오즈비 ; '일어나지 않을 확률' 분의 '일어날 확률') 에 로그를 씌운 형태이다. 여기서 우리가 추정한 '일어날 확률'은 뚝딱뚝딱 계산해보면 아래와 같다 :
$$ \hat\pi(X) = \frac{\exp(\beta_0 + \beta_1 X)}{1 + \exp(\beta_0 + \beta_1 X)} $$
얘를 시그모이드(sigmoid) 함수라고 부른다. 그냥 지수함수, 로그함수와 같은 고유명사다.
위의 그림에서 마젠타색 곡선은 X에 대한 시그모이드 곡선이다. 다시 말해서, 저 곡선이 나타내는 값은 '그 X값에서의 성공 확률'을 의미한다. 딴 게 아니고, 방금 수식으로 적은 시그모이드 함수를 데이터 플롯에 그리면 저렇게 나온다는 것이다.
이렇게 복잡하게 생각하면 머리아프니까, 저 그래프의 함숫값이 대충 '어떤 사건이 일어날 확률' 이라고 생각해도 좋다. 위 그림에서는 X가 증가하면서 확률이 증가하는구나, 하는 식으로.
더 나아가, 이렇게 확률을 fitting 하고 나서야 우리는 아까 선형 모형에서 하려고 했었던 일, 그러니까 적당한 함숫값을 기준으로 0으로 보내거나 1로 보내거나 하는 X의 경계선을 결정할 수 있다 (이게 데이터 과학 분류 문제의 soft classification이다. 혹시 논문같은 데서 배경지식으로 알아두면 좋을지도 몰라 적어 두었지만, 사실 몰라도 된다) .
예시는 따로 추가하지 않겠지만, 앞서 언급했던 '횟수(count, 세포 수 등)' 데이터의 경우도 마찬가지로 적용하면 된다.
카운트 데이터는 태생이 '양의 정수(실수) 범위' 이기 때문에, 로짓 펑션을 만드는 과정에서 했던 것처럼 숫자에 로그만 취해주면 숫자가 실수 전체로 퍼지게 된다. 그걸 선형 회귀로 피팅하면 된다. 이걸 '로그-선형 회귀 모형 (log-linear regression model)' 라고 부른다.
그리고 이렇게 다양한 데이터 상황에 맞게 선형 회귀를 잘 매만져준 로지스틱, 로그 리니어 등의 다양한 모델들을 묶어서 "GLM (Generalized Linear Model)" 이라고 부른다.
(베르누이니 포아송이니 와 같은 link function 이야기는 여기서는 하지 않겠다. 단순히 선형 회귀에 뭔가를 씌워서 이런 식으로 이용한다는 느낌을 전달하고자 하는 게 목표이기 때문에. 궁금하면, 또 구글에 좋은 소스들이 많이 있다)
이런 이야기는 단순히 분석에만 국한되지 않는다. 함수 식을 결정했다는 건 새로 들어오는 인풋 데이터 X에 대해 반응 변수 Y 값을 예측할 수 있다는 뜻이다. 이걸 하는게 머신러닝과 딥러닝이다. 정말 단순하게 치환한다면, 지금 세상에 나와 있는 뉴럴넷이나 앙상블 등 다양한 "정답이 존재하는" 예측 / 분류 문제도 이와 같은 맥락에서 출발해 볼 수 있다.
# 위에서 쓴 binom 데이터 만들기. fit7의 estimates와 비교해보면, 나름 잘 맞았다.
set.seed(123)
X = runif(100, -10, 10) ; B = numeric()
for(i in 1:100){
p = function(x) exp(1 + .5*x) / (1 + exp(1 + .5*x))
B[i] = rbernoulli(1, p(X[i]))
}
df = tibble(X = X, B = B)
5. 마치며
최근에 적지 않은 대학 동기들 / 지인들로부터, 거의 내가 도라에몽이 된 것 마냥 R 혹은 통계와 관련한 질문을 많이 받았다. 주로 논문을 보다가 뭔가 나왔는데, 찾아봐도 모르겠어서 도와 달라는 구원 요청이었다.
보통 그럴때 쓰는 레퍼토리가 있는데, 바로 위에서 소개했던 '선형 회귀 모형'을 n차원 공간 속의 p차원 데이터 스페이스부터 시작해서, 뭐를 어디로 프로젝션(정사영) 시키면 뭐가 되고 residual은 어떤 벡터고 그래서 SST가 SSE랑 SSR이 어떤 벡터의 L2 norm이니까 어쩌고... 하는 어려운 내용을 짧은 시간에 쫙 늘어놓는 것이다 (이 내용은 위에서 하나도 다루지 않았다). 당연히 알아먹으라고 하는 말은 아니고 일종의 충격 요법인데, 당신이 지금 물어본 걸 정확하게 이해를 할거면 당신이 대충 보고 치웠던 회귀부터 다시 보시고, 아니면 그냥 머리가 아닌 가슴으로 받아들이고 쓰라는 이야기를 덧붙인다. 그리고 나서 원하던 걸 짤막하게 풀어서 설명해주면 대부분 일단 넘기고 다음에 공부하는 쪽을 택한다 (보통 어지간히 고민해도 답이 안나오는 복잡한 방법들은 그렇게 사전 지식 없이 간단하게 설명할만한 게 아니다. 일단 지금까지 내가 본 건.)
그러니, 통계 공부를 해야 할 것 같긴 한데 뭐부터 해야 할지 모르겠다 하면, 일단 회귀부터 다시 보자. 사전 지식으로 회귀를 들고 있으면 꽤나, 아니 상당히 많은 부분을 커버할 수 있다. 차원 축소니 뭐니 하는 건 그 다음이다.
끝.