
- 확률(Probability)의 재정의
- 통계와 통계량(Statistics)
- 샘플링(Sampling)과 확률 변수(Random Variable)
- 확률 함수: cmf / cdf / pmf / pdf
- 선형대수 표시법: Matrix를 왜 쓰는가?
- 데이터와 차원의 표현: 정보의 압축
- 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset)이다
- Bernoulli Trial: Binomial, Geometric, Hypergeometric, Negative binomial distribution
- Poisson Process: Exponential, Gamma, Beta distribution
- 추정(Inference): 귀무가설과 대립가설, 유의 수준과 p-value, 신뢰구간(CI)
- 추정(Inference) (2): Pivotal quantity, Student-t, Chi-square, F test and ANOVA table
- Experiment prediction: 회귀분석(Regression Analysis)의 가정(assumptions)과 아이디어
- Appendix
1. 왜 매트릭스?
내내 확률 얘기만 하다가 갑자기 공기가 바뀌었습니다. 잠시 리프레쉬도 좀 할 겸 선형대수를 왜 알아야 하는지, 제가 느낀 바를 공유드리려고 해요.
Matrix, 행렬이라는 형태 자체를 모르시는 분은 많지 않으리라 생각합니다.
$$\begin{pmatrix} 1 & 2 \\ 3 & 2 \end{pmatrix}$$
이처럼 행(row, 가로 줄)과 열(column, 세로 줄)의 형태로 정보를 담은 이러한 형태를 '행렬' 이라고 부릅니다.
목적부터 설정해 봅시다. '행렬'이라는 형태가 왜 중요할까요? 획기적으로 계산이 편해서일까요?
사실 대학에 오셔서 선형대수를 들으셨던 분들이시라면 도저히 그렇게 느끼지 못하셨을 거예요. Gauss Jordan이니, Eigenvector니 eigenvalue니, Gram-Schmidt 니 뭐 이상한 것들도 많이 튀어나오고 시험 시간도 부족하던데. 아 저만 그랬을지도 모릅니다만.

결론적으로 매트릭스를 쓰는 이유는, 단순히 데이터 저장을 그렇게 하기 때문입니다. 컴퓨터가 계산하기에 이게 편하대요.
(그걸 선형대수 시간에는 저희 손으로 풀라고 하니, 불편할 수 밖에 없...다고 제 학점을 위로해 봅니다)
1-1. 기본적인 데이터 구조
뭐 여기저기서 많이 쓰는 단어이기 때문에 많은 분들께서 이미 알고 계실 내용이지만, 간단하게 짚어 보겠습니다.
여기 하나의 숫자가 있습니다.
$$188$$
대충 제 (희망) 키네요.
이런 하나의 숫자를 뭐라고 부를까요?
그냥 키죠 뭐.
'스칼라' 라고 말씀해주시는 분들도 계실 겁니다. 물론 틀렸다고 할 정도는 아니지만, '스칼라'라는 단어의 의미를 조금만 정확히 들여다 보도록 해요.
스칼라(Scalar)는 일반적으로 벡터의 반대 개념으로 많이 쓰입니다만, 정확히는 '스케일러' 와 같은 발음으로 의미를 더욱 정확히 보일 수 있습니다. 스칼라는 'Scale' 에서 나온 말로, 대충 '곱해주는 상수' 정도의 자격을 지닙니다.
그러니까, 스칼라는 '이름' 보다는 '직책'이라고 이해해주시면 좋을 것 같습니다. 어떤 수 a가 벡터 혹은 매트릭스와 곱해졌을 때, a를 스케일러라고 부르는 게 자연스러운 그런 느낌...입니다.
대학생 이자라 씨를 동네 마트에서 만났을 때 보통 "자라씨!" 라고 부르지, "대학생!" 하고 부르면 틀린 말은 아니지만 정이 좀 없어 보이잖아요.
제 키에 저희 학과 네 명의 키를 더 조사해서 메모해 두었습니다.
$$\begin{pmatrix} 188\\164\\183\\172\\177 \end{pmatrix}$$
이 정보는 모두 '키'라는 공통된 속성을 갖고 있습니다. 이 '키' 정보를 편하게 저장하려는 목적으로, 우리가 다섯 개의 수를 묶어 둔 것이죠.
고등학교때 배운 벡터로 우리는 보통 화살표를 떠올리기도 합니다. 물론 직관적으로 visualizing하는 것이 정보를 다루는 데 굉장히 도움이 많이 됩니다만, 벡터(vector)는 기본적으로 '화살표' 보다는 '숫자의 묶음' 으로서 의미를 갖습니다.
고등학교 수학에서 '기하와 벡터'라는 과목을 하셨던 늙은이 분들께서 평면 벡터, 공간 벡터까지만 배운 건 우리가 거기까지밖에 그릴 수 없기 때문입니다. 4차원의 벡터를 그리려면 4차원의 공간을 먼저 그려야 하는데, 되시는 분들도 계시지만 저를 포함한 대다수 분들께서는 그거 어떻게 그리는지 모르잖아요. 그런데 단순히 벡터를 '숫자의 묶음'으로 생각하시면, 벡터라는 것 자체는 그리 어렵지 않습니다.
저도 수능을 봤던 두 번 모두 수학 가형의 29번 문제가 공간벡터 문제였던지라, 벡터 문제만 보면 우선 좌표계를 그리고, 벡터의 움직임을 좌표에 표현해 보는 방식으로 접근했던 걸로 기억합니다. 그렇지만 이제 벡터 생각 할 때, 그림을 필요하면 찾는 정도로 내려두는 것이 좋은 게, 앞으로 우리가 다루는 '데이터'에서의 벡터는 수 십에서 수 백, 수 천 차원씩 되기 때문이예요. 그 수 백, 수 천 차원의 좌표계를 그릴 수 있는 게 아니라면 벡터를 있는 그대로, 일단 숫자의 묶음으로 '만' 생각하자구요, 우리.
자, 이제 우리 스칼라와 벡터를 이야기 마저 할 수 있겠습니다.
우리의 키 벡터
$$v=\begin{pmatrix} 188\\164\\183\\172\\177 \end{pmatrix}$$
를 m(미터) 단위로 바꾸고 싶어요. 곱하기 0.01을 해주면,
$$\frac{1}{100}v=\begin{pmatrix} 1.88\\1.64\\1.83\\1.72\\1.77 \end{pmatrix}$$
이 때 곱해주는 수인 0.01을 scalar라고 이야기 할 수 있겠습니다.
미세 팁입니다만, 벡터는 관습적으로 column 형태로 씁니다. row vector를 표시할 때는 윗첨자로 T를 붙여서 다음과 같이 표시하는데, 곧 매트릭스 노테이션과 함께 다시 한 번 짚도록 해요.
$$v=\begin{pmatrix} 188\\164\\183\\172\\177 \end{pmatrix}$$
$$v^T=\begin{pmatrix} 188 & 164 & 183 & 172 & 177 \end{pmatrix}$$
친구가 제 키 벡터의 164라는 숫자를 보고 "이 분 키가 좀 작으시네" 합니다.
놀랍게도 164는 여자분의 키였어요. "너랑 말을 섞어주시는 여성분이 계시단 말이냐?" 하지만, 이 악물고 쿨한 척을 해봅니다.
한 번만 더 이렇게 팩트로 뼈를 맞으면 진짜 울 것 같아서, 저는 키 정보 옆에 성별 정보를 표시하기로 합니다.
알파벳 순서대로 Female을 0, Male을 1로 표시해서 column을 추가하고, '데이터' 앞글자를 따서 D라고 이름을 붙여 봤어요.
$$ D= \begin{pmatrix} 188 & 1 \\ 164 & 0 \\ 183 & 1 \\ 172 & 0 \\ 177 & 1 \end{pmatrix} $$
드디어 우리가 알고 있던 매트릭스의 형태가 되었습니다.
각 column은 각각 '키', '성별'을 나타내고, 이걸 우리는 변수(Variable) 라고 부릅니다. 수학적으로 엄밀하게 따지고 들어가면 복잡하(고 귀찮)지만, 일반적으로 회귀 분석등의 분석을 진행할 때 매트릭스의 차원(dimension)은 변수의 개수와 같다고 상정하고 분석을 진행하는 편이예요(결과에 문제가 생기면 retrospect 해보고 적절한 조치를 취해줍니다). 보다 엄밀하고 수학적인 백그라운드가 필요하시다면, 고작 인터넷에서 이따위 글을 통해 공부하시는 것 보다는 많은 학과에서 1학년 대상으로 열리는 교양 선형대수 과목을 수강하시는 것도 좋습니다 (저도 타 학과 강의를 수강했습니다).
또한, 저는 0과 1로 표시했습니다만 글자 값 그대로 'M', 'F' 등의 성별 표시를 넣어주는 경우도 있습니다. 매트릭스는 계산을 위해 사용하는 수학 도구이지만, 이처럼 글자를 넣는 경우는 맨 처음의 데이터 예시처럼 'data frame'을 만들어 줍니다. 이 때 맨 윗줄에 들어가는 변수 이름(country, year, ... )을 '헤더(header)' 라고 부릅니다. 데이터 프레임의 경우는 지금 이 기초 통계학 내용에서는 다룰 일이 없지만, 결국 많은 필드에서 df의 형태로 데이터를 많이 생성하기 때문에, R 등으로 df를 다루는 방법도 배워 두면 편하실 지도 몰라요. 개인적으로는 기초통계학 이후 R의 'tidyverse' 메뉴얼을 정리해 볼 계획에 있습니다.
자료를 이러한 방식으로 저장하면 어떤 이점이 있을까요?
제가 키를 조사하는 뻘짓을 한다는 소식을 들으시고, 분노하신 교수님께서 저를 찾아 오셨습니다.
"내 키는 175다 !"
뭐지 몰카인가? 싶지만, 일단 저는 데이터를 추가하기로 했습니다. 매트릭스 아래에, 왼쪽 변수에 '175', 오른쪽 변수에 '1'을 넣습니다.
$$ D= \begin{pmatrix} 188 & 1 \\ 164 & 0 \\ 183 & 1 \\ 172 & 0 \\ 177 & 1 \\ 175 & 1 \end{pmatrix} $$
그러고 보니, 새 데이터를 추가할 때 기존에 있던 데이터는 전혀 건드리지 않았네요.
이렇게 데이터를 저장하는 방식을 'Long format' 이라고 부릅니다. 비슷하게, obs(obsevation, 관측치)가 옆으로 추가되는 형태를 'wide format' 이라고 불러요. 롱 포맷의 장점은, 변수만 늘려 가면 데이터의 작성이 쉽다는 것입니다. 또한 각 관측치의 정보가 개별적으로 표시되어 있기 때문에, 데이터의 가공과 정리가 쉬워요.
대충 조사를 마치려던 무렵, 옆 학과에도 저처럼 본인 학과 학우들의 키를 조사하고 있었던 분이 계신 걸 알게 되었습니다.
두근대는 가슴을 진정시키며, 데이터를 요청해 받아 왔습니다. D2라고 하네요.
$$ D_2= \begin{pmatrix} 168 & 1 \\ 157 & 0 \\ 189 & 1 \\ 174 & 1 \\ 158 & 0 \\ 187 & 1 \end{pmatrix} $$
제 D와 방금 받아온 D2는 대충 비슷한 테마를 연구한 데이터예요. 저는 이걸 한번에 묶고 싶습니다.
이렇게, 다층적으로 2차원 데이터를 묶은 형태를 '어레이(array)' 라고 합니다. 아래와 같은 3차원의 데이터 공간을 생각하시면 됩니다.
바이오 데이터에서는 어세이(Assay)라는 단어로 많이 쓰기도 합니다.
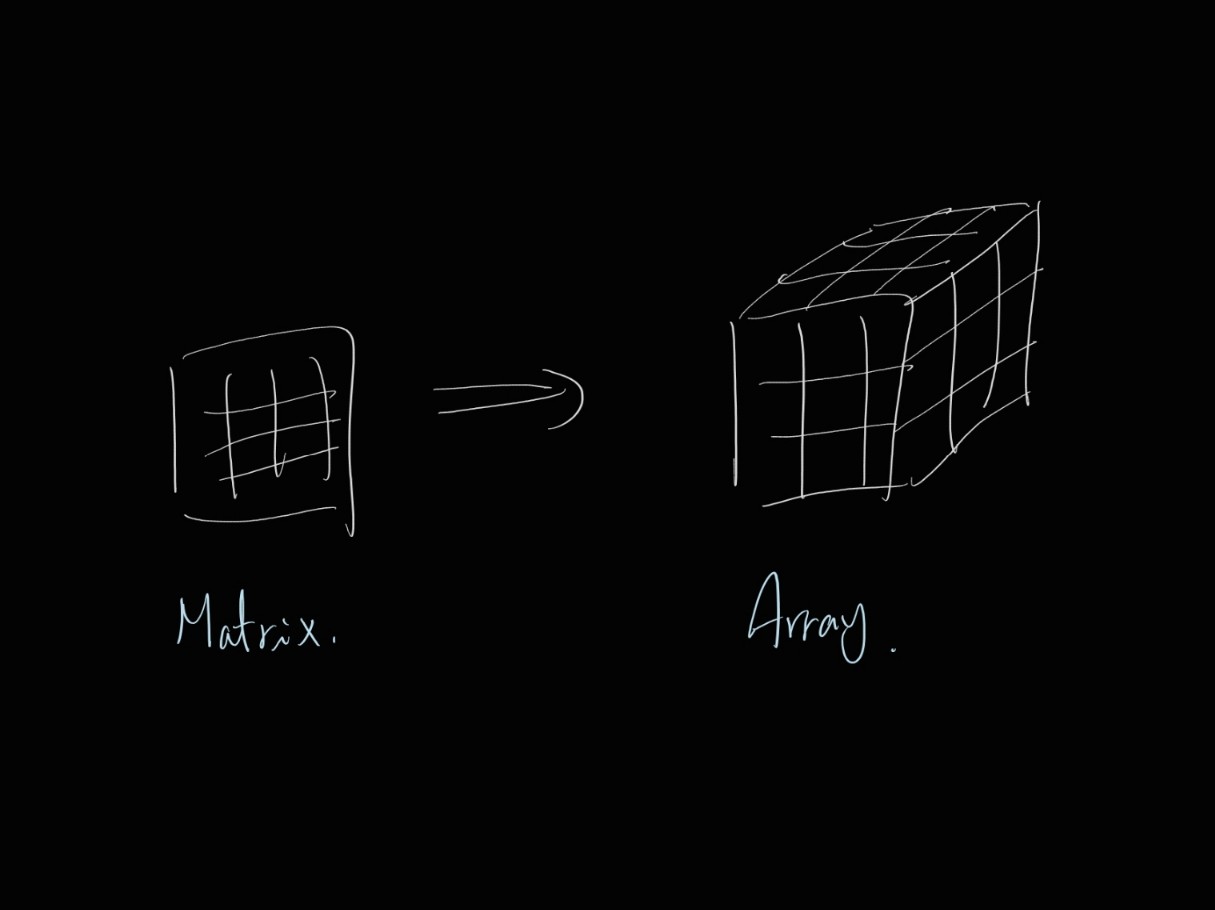
2. Matrix Notations
어려운 연산을 하자는 건 아니고, 간단한 기호들, 그리고 표시법 들만 메모하도록 하겠습니다.
계산하는 법이나 유용한 properties 등은 강의를 들으시거나, 구글링으로 더 깊고 자세한 정보를 살펴 보시거나, 주변에 잘 아는 공대생 분들께 여쭈시면 훠어얼씬 도움이 될 것 같습니다.
2-1. Matrix 덧셈
먼저 아주 간단한 연산들을 보도록 할게요.
매트릭스의 덧뺄셈은 같은 위치에 있는 원소(element)끼리 계산합니다.
$$ \begin{pmatrix} a & b \\ c & d \end{pmatrix} + \begin{pmatrix} x & y \\ z & w \end{pmatrix} = \begin{pmatrix} a+x & b+y \\ c+z & d+w \end{pmatrix} $$
2-2. Inner product
어디서든 '행렬' 혹은 '벡터'에 관한 이야기를 들어보셨던 분이라면 아마 아실 것 같은, '내적'이라는 것입니다.
A와 B라는 매트릭스가 있을 때, 이들의 곱은 다음과 같이 씁니다.
$$ AB $$
일반적인 매트릭스의 '곱'은 이처럼 곱하기 기호를 생략하는데요, 곱하기 기호는 outer product 라는 다른 연산을 의미하기 때문이예요.
이너프로덕트는 다음과 같은 방식으로 연산을 진행합니다.
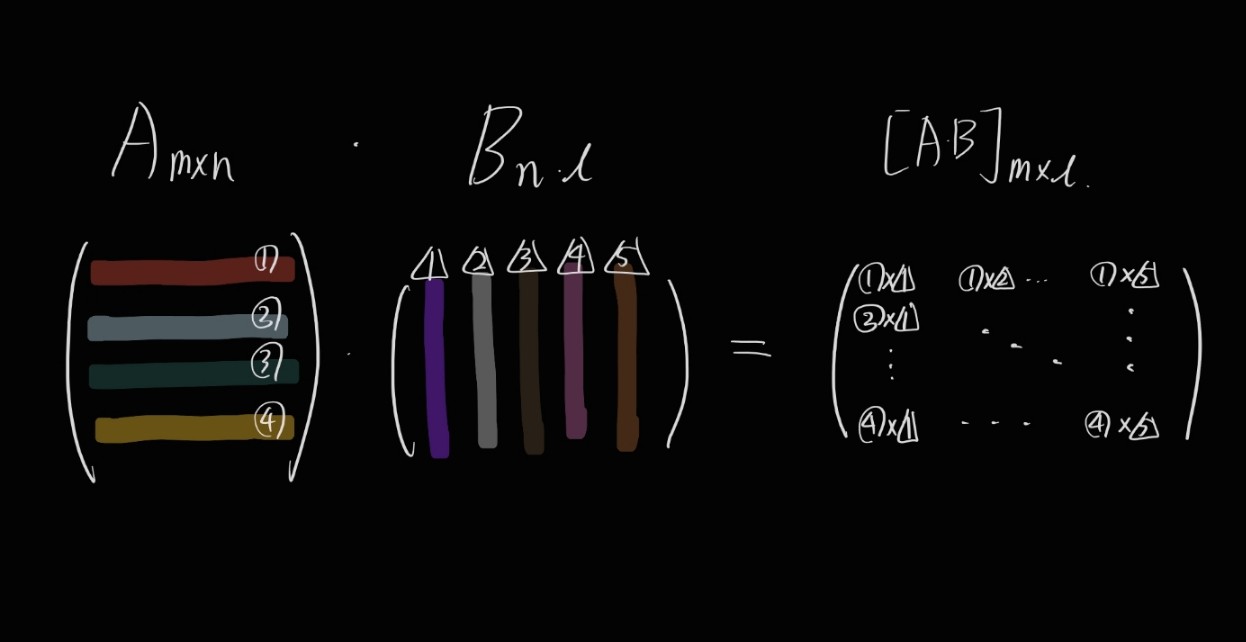
매트릭스 A는 m개의 row와 n개의 column을,
매트릭스 B는 n개의 row와 l개의 column을 갖고 있습니다. 이러한 경우에만 이너프로덕트가 가능해요.
그랬을 때 연산 결과의 매트릭스는 m개의 row와 l개의 column을 갖게 됩니다.
풀어 쓰면,
$$ A=\begin{pmatrix} a & b & c \\ d & e & f \end{pmatrix} $$
$$ B= \begin{pmatrix} s & t \\ u & v \\ x & y \end{pmatrix} $$
일 때,
$$ AB = \begin{pmatrix} as+bu+cx & at+bv+cy \\ ds+eu+fx & dt+ev+fy \end{pmatrix} $$
이러한 방식으로 하는 연산을 매트릭스의 이너프로덕트라고 합니다.
보시면 아시겠지만, 이러한 연산 과정에서 매트릭스의 방향은 굉장히 중요합니다. 매트릭스의 row와 column의 수에 따라서 연산이 되고, 안되고 부터 결정이 되기 때문이예요.
그래서 이런 매트릭스 형태에 관한 노테이션도 몇 가지 살펴보겠습니다.
2-3. Matrix 형태에 관한 Notation
2-3-1. Square matrix
Square는 보통 수학을 많이 접하시면 '제곱' 이라는 뜻으로 사용하지만, 아시다시피 '정사각형'을 의미하기도 합니다.
스퀘어 매트릭스는 말 그대로 row와 column의 수가 같은 매트릭스를 말합니다.
$$ \begin{pmatrix} a&b&c \\ d&e&f \\ g&h&i \end{pmatrix} $$
뭐 basis니 pivot이니 LU factorization이니 하는 것들은 집어 치우겠습니다. 지금은 선형대수 시간이 아니니까요.
대충 선형 방정식(=매트릭스와 벡터로 이루어진 방정식, \( Ax=b\) ) 을 풀 때 이 스퀘어 매트릭스를 적절히 잡고 시작한다! 정도의 느낌으로 퉁치고, 이런 기본적인 선형대수 내용은 간단한 구글링으로도 좋은 자료들을 많이 접하실 수 있을 테니 넘어가겠습니다.
기회가 되면, 후에 바이오, 공학 계열 뿐만 아니라 경영 공학 분야에서도 많이 사용하는 OR(Operations Research, 다양한 최적화 문제를 다루는 과목입니다) 의 멋진 아이디어들도 소개할 수 있으면 좋겠네요. 쌩 수학이긴 합니다만
2-3-2. Transpose
Transpose, 전치행렬 이라고 합니다.
행렬 A의 전치행렬이란, A의 대각선을 축으로 종이접기 하듯 자리를 바꾼 것을 의미합니다.
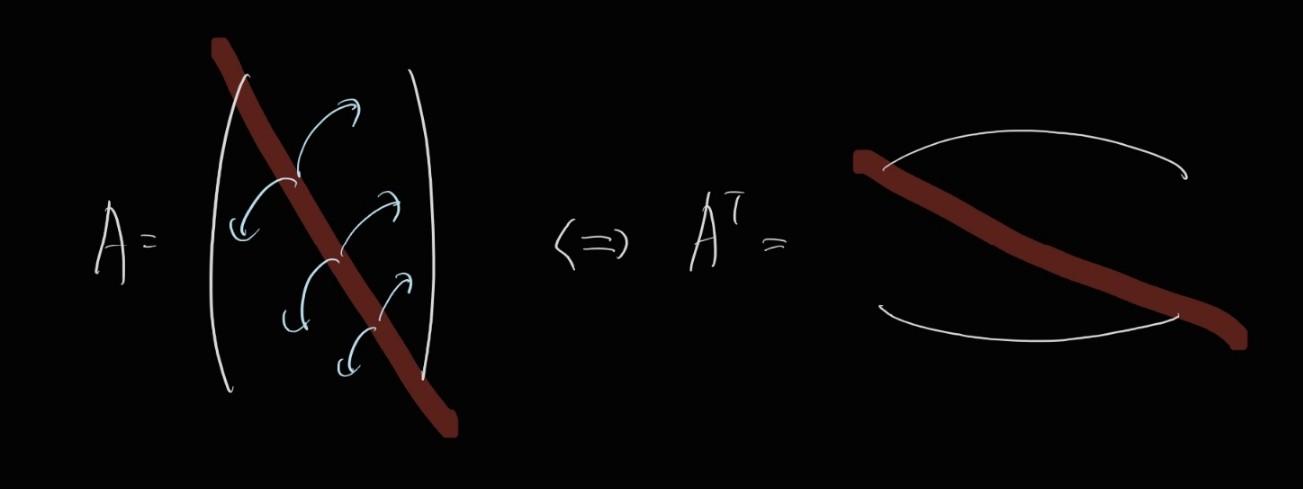
실례로 보면,
$$ A= \begin{pmatrix} a & b & c \\ d & e & f \end{pmatrix} \Leftrightarrow A^T= \begin{pmatrix} a & d \\ b & e \\ c & f \end{pmatrix} $$
와 같은 식입니다.
저 위의 사례에서 보셨듯 column이 한 개인 'column 벡터' 의 경우에는 row 벡터로 치환됩니다.
2-3-3. Inverse matrix와 Identity matrix
먼저 Identity matrix는, 매트릭스 계의 1에 해당하는 놈입니다.
주로 "I(아이)" 라는 노테이션으로 쓰며,
$$AI=A$$
가 되는 매트릭스입니다.
대각선에만 원소가 있는
$$ \begin{pmatrix} a&0&0 \\ 0&b&0 \\ 0&0&c \end{pmatrix}$$
와 같은 놈들을 diagonal matrix(대각 행렬, diagonal이라는 말 자체가 대각을 뜻합니다) 라고 하는데,
I는 대각의 원소가 모두 1인 square matrix 입니다. 즉,
$$ I= \begin{pmatrix} 1&0&0&0 \\ 0&1&0&0 \\ 0&0&1&0 \\ 0&0&0&1 \end{pmatrix} $$
처럼 생긴 행렬은 모두 identity matrix 입니다.
역행렬(inverse matrix)도 개념적으로는 어렵지 않은데, 역함수와 비슷한 개념입니다.
우리
$$ f(g(x))=x $$
라면,
$$g(x)=f^{-1}(x) $$
라는 걸 알고 있죠.
마찬가지로, A의 역행렬은 다음을 만족합니다 :
$$ A^{-1}\; : \; AA^{-1}=A^{-1}A=I $$
물론 모든 매트릭스가 역행렬을 갖는 건 아닙니다. 우리는 singularity라는 property를 갖는 매트릭스의 역행렬을 이야기 할 수 있는데, 역시 선형대수학에서 다뤄야 할 내용이므로, 우리는 그냥 이걸 공학용 계산기나 R을 통해 간단하게 얻을 수 있다! 정도만 보면 되지 않을까 싶어요,
solve(A) #R에서 역행렬 구하는 코드입니다.
2-3-4. 벡터의 제곱
다음과 같은 벡터를 생각해봅시다.
$$ v= \begin{pmatrix} 3\\4 \end{pmatrix} $$
이 벡터의 크기는 어떻게 구할 수 있을까요?
좌표에 평면 벡터를 표시해 보면 크기가 5인 것을 알 수 있습니다.
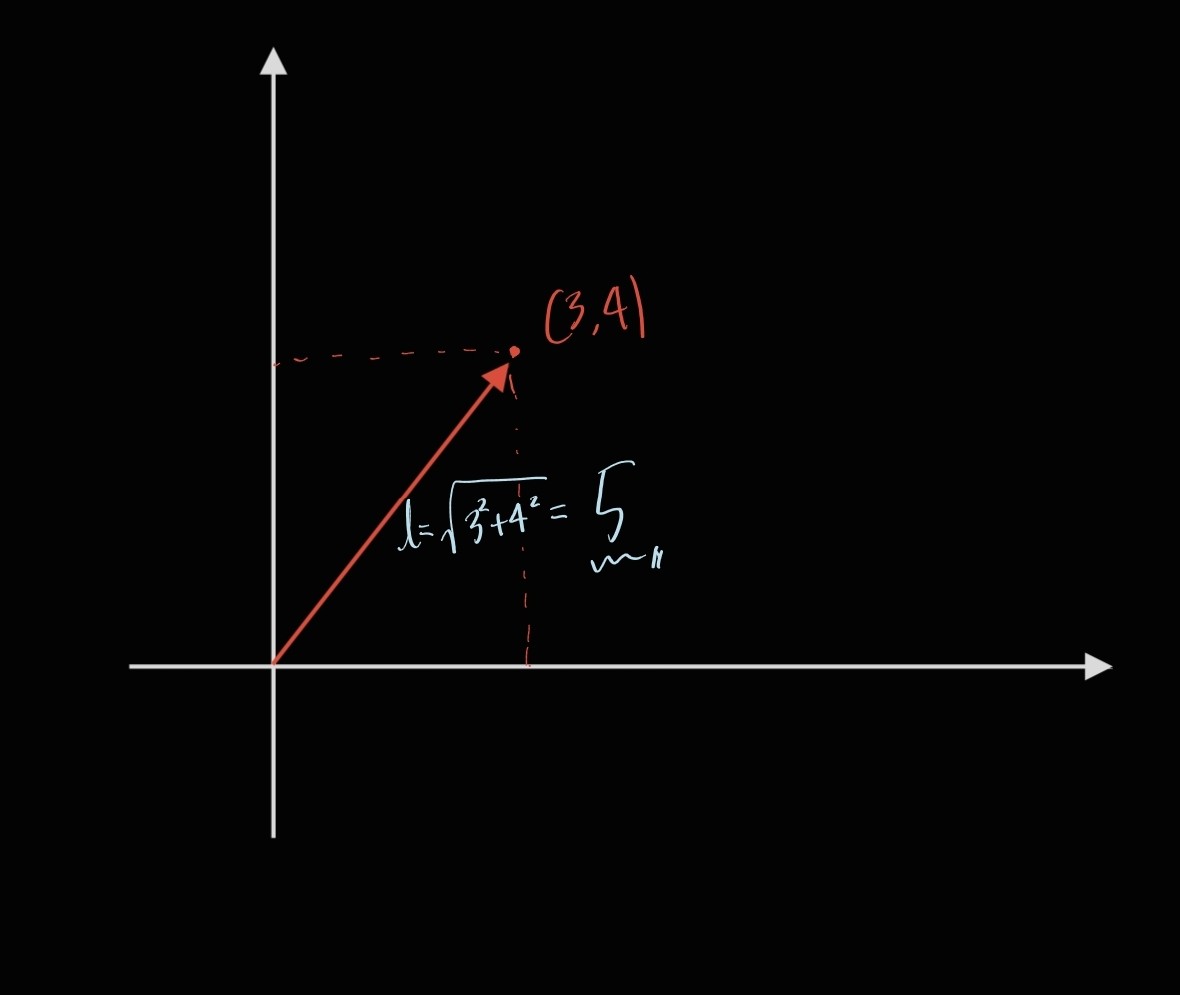
이 연산을, 위에서 살펴본 연산으로 어떻게 표시할 수 있을까요?
벡터의 곱, inner product를 이용하면 다음과 같이 표현할 수 있을 겁니다.
$$ v^Tv= \begin{pmatrix} 3 & 4 \end{pmatrix} \begin{pmatrix} 3\\4 \end{pmatrix} = 3^2+4^2=5$$
마찬가지로, 3차원 공간의 벡터
$$ u= \begin{pmatrix} 3 \\ 4 \\ 5 \end{pmatrix} $$
에 대해 그 크기는
$$ u^Tu= \begin{pmatrix} 3 & 4 & 5 \end{pmatrix} \begin{pmatrix} 3\\4\\5 \end{pmatrix} $$
처럼 나타낼 수 있습니다.
이 얘길 왜 넣었냐면, transpose 등의 처리는 특별할 때 넣는다기 보다는 그냥 우리가 필요할 때 이용할 수 있다! 는 걸 소개해드리고 싶어서 였습니다.
선형대수 내용을 전혀 다루지도 않을 거면서 매트릭스에 관한 포스트를 따로 굳이 넣은 이유도 여기에 있어요.
어찌됐든, 일정한 수준의 통계학에 관심이 있어 이 포스트를 읽고 계시는 분이라면,
반드시 데이터를 처리함에 있어 매트릭스의 구조, 그리고 연산이 돌아가는 모양새를 이해할 필요가 있다고 생각합니다.
상술했듯 우리의 데이터가 매트릭스의 형태를 취하기 때문이고,
단순한 t-test 내지 Simple linear regression(변수를 하나만 잡는 선형 회귀 분석. 즉 실험의 결과를 결정하는 원인이 단 하나밖에 없다는 건데, 일반적으로 우리 실험 상황에서 그럴 리가 없겠죠) 만 볼 게 아니라면 반드시 분석 과정에서 매트릭스의 연산을 필요로 할 거예요.
그래서, 앞으로 제가 작성하는 기초 통계학 시리즈에서 매트릭스를 이용한 분석 기법을 소개해 드리진 않지만,
일단 형태 자체에 익숙해지는 건 기초 단계의 과정에서 필요하다고 생각했습니다.
언제 어디서 매트릭스 관련 내용이 나와도, 공부하면 할 수 있다! 라는 생각이 들 수 있도록 말이죠.
한참 부족한 내용이지만 매트릭스를 그야말로 '생전 처음 본다' 는 가정 하에 소개만 해드리는 정도로 이만 줄이고,
다음 시간에는 이와 관련하여 분석과 visualizing에서 중요한 아이디어 중 하나인, 데이터의 '차원' 이라는 것에 대해서 간단하게 제 생각을 나눠보는 내용을 준비해 보겠습니다. 제가 처음 데이터를 다루기 시작했을 때 갖고 있던 고정 관념에 관한 것이기도 하고, 이 테마로 이야기를 나눠보는 것 자체만으로 아마 논문의 피겨를 보실 때 그 해석에 조금이나마 도움이 되실 거라 생각하는 내용입니다.
(네 사실 이 많은 매트릭스 수식을 마크다운으로 하나씩 치려니 헷갈려 죽겠습니다. 다른 내용보다 두 배로 힘든 것 같아요)
'Z-bio stat > Z-기초통계학' 카테고리의 다른 글
| [Z-bio Stat] 7. 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset) 이다 (0) | 2023.01.01 |
|---|---|
| [Z-bio Stat] 6. 데이터와 차원의 표현: 정보의 압축 (0) | 2022.12.29 |
| [Z-Bio Stat] 4. 확률 함수 : cmf / cdf / pmf / pdf (0) | 2022.11.28 |
| [Z-Bio Stat] 3. 샘플링(Sampling)과 확률 변수(Ramdom Variable) (0) | 2022.11.20 |
| [Z-Bio stat] 2. 통계와 통계량(Statistics) (0) | 2022.11.07 |



