
- 확률(Probability)의 재정의
- 통계와 통계량(Statistics)
- 샘플링(Sampling)과 확률 변수(Random Variable)
- 확률 함수: cmf / cdf / pmf / pdf
- 선형대수 표시법: Matrix를 왜 쓰는가?
- 데이터와 차원의 표현: 정보의 압축
- 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset)이다
- Bernoulli Trial: Binomial, Geometric, Hypergeometric, Negative binomial distribution
- Poisson Process: Exponential, Gamma, Beta distribution
- 추정(Inference): 귀무가설과 대립가설, 유의 수준과 p-value, 신뢰구간(CI)
- 추정(Inference) (2): Pivotal quantity, Student-t, Chi-square, F test and ANOVA table
- Experiment prediction: 회귀분석(Regression Analysis)의 가정(assumptions)과 아이디어
- Appendix
오늘 토픽은 정말 수박 겉핥기로 넘어갈 수 밖에 없을 것 같지만...
실제 연구에서 꽤 자주 볼 수 있는 아이디어이니 짧고 굵게 짚고 가도록 하겠습니다.
퇴근하고서 간만에 슬기가 넘치는 의학드라마 정주행 하고 있으니 너무 재밌네요.
1. Plotting
이라는 단어에 대해서 좀 보겠습니다. 코딩 경험이 없으신 분께서는 한 번도 이 단어를 접해보지 못하신 분들도 계실 거예요.
'플롯(Plot)' 은 간단히 논문에 나온 피겨를 이야기합니다.
그리고 이걸 그리는 행위를 '플롯팅(plotting)' 이라고 합니다. 플러팅은 못하지만 플롯팅은 잘 하는 남자
플롯에는 다양한 종류가 있습니다.
갈수록 마크다운으로 수식이 점점 많아지면서 이 시리즈 때려 쳐버릴까 고민을 좀 했는데 이번엔 그림그리기라니.
데이터도 딱히 없는데 점점 배보다 배꼽이 더 커지네요. 아이고 두야
처음으로 보실 건 히스토그램 입니다.
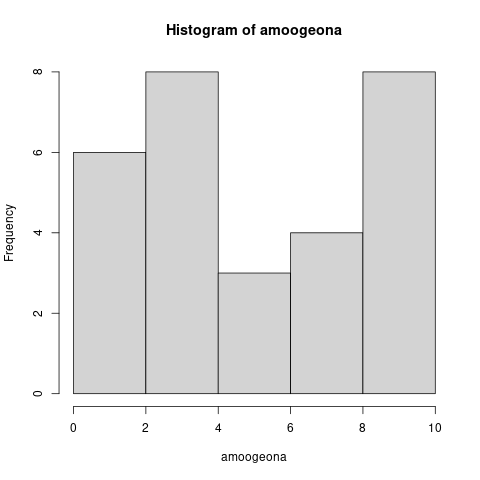
아시다시피 히스토그램은 어떤 데이터의 수량을 나타낸 그림입니다.
즉, x축의 각 요소들의 수량이라는, 딱 한 가지의 정보만을 나타내고 있습니다.
히스토그램을 축이 하나만 있는 데이터, "1차원 데이터" 라고 부르겠습니다.
다음은 box plot 입니다.
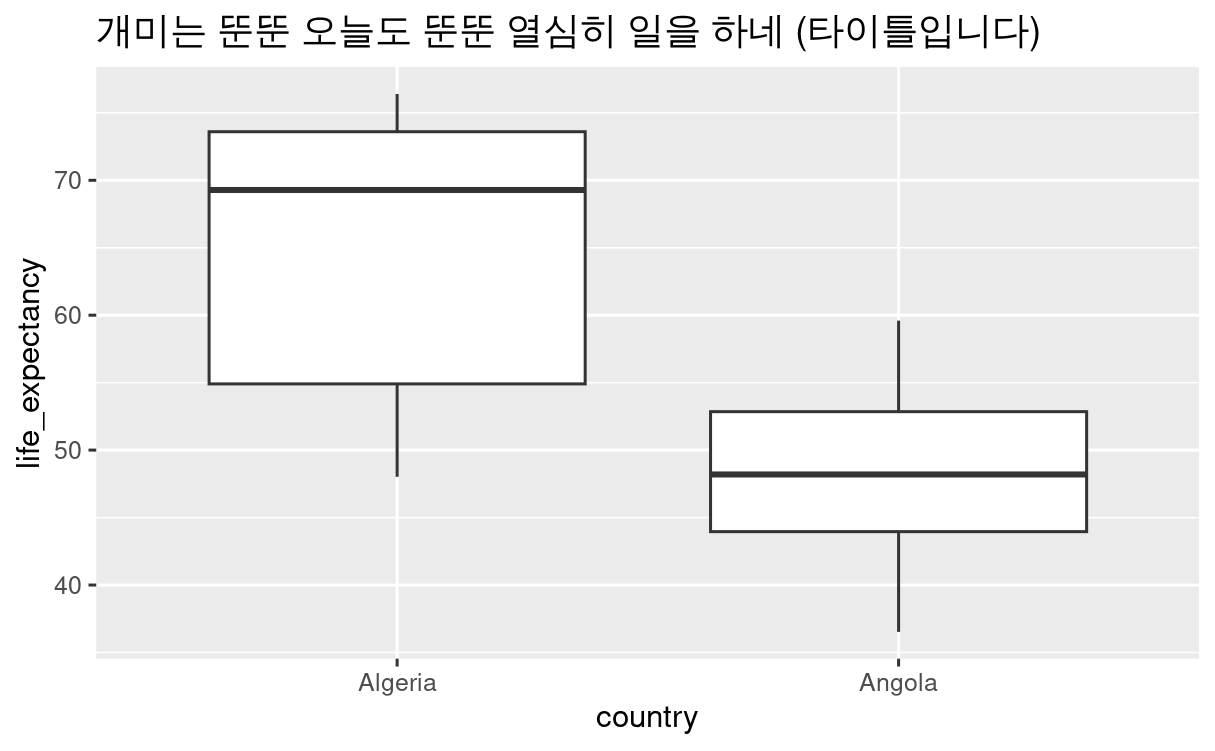
박스 플롯은 discrete 데이터인 x축과, continuous 데이터인 y축을 보여줍니다.
이 외에도 흔히 접하는 꺾은선 그래프나 스캐터 플롯 등도 x축과 y축으로 두 가지 정보를 담아 냅니다(걔들은 x축도 continuous 데이터일 때 선택하는 게 좋겠습니다).
이러한 것들을 두 가지 축을 사용하는 데이터, "2차원 데이터" 라고 부릅니다.
아, 플롯에서 보여주고 싶은 변수의 수에 따라서 축을 하나씩 늘려 가는구나!
그럼 3차원, 4차원, 그보다 고차원의 데이터로 그린 플롯을 잘 해석하려면 다양한 플롯을 종류별로 많이 익혀 둬야겠군!
이런 방향은, 제 개인적으로는 다가가기 어려운 방향이었습니다.
플롯이나 피겨는 내용을 쉽게 알아보라고 넣어 둔 보조자료니까, 직관적이고 쉽게 이해할 수 있어야 하지 않나 싶어요(절대 제가 바보라서 남 탓하는 것 맞습니다).
그리고 안타깝게도 우리 페이퍼는 2차원 종이에 출력됩니다.
다시 말해 우리 머리로는 2차원보다 큰 공간, 예를 들어 3차원 공간을 상상하고 플롯팅을 할 수는 있겠지만, 그걸 2차원 종이에 그리는 순간 어쩔 수 없이 왜곡이 발생해요. 독자가 보자 마자 직관적으로 받아들일 수 있는 게 아닌, 3차원 공간을 상상해서 머릿속으로 그림을 상하좌우로 돌려보고 이해하는 과정이 필요하다는 거죠.
그래서 보통 제일 먼저 떠올릴 수 있는 세번째 축은 z축이 아닌, '색깔' 입니다.
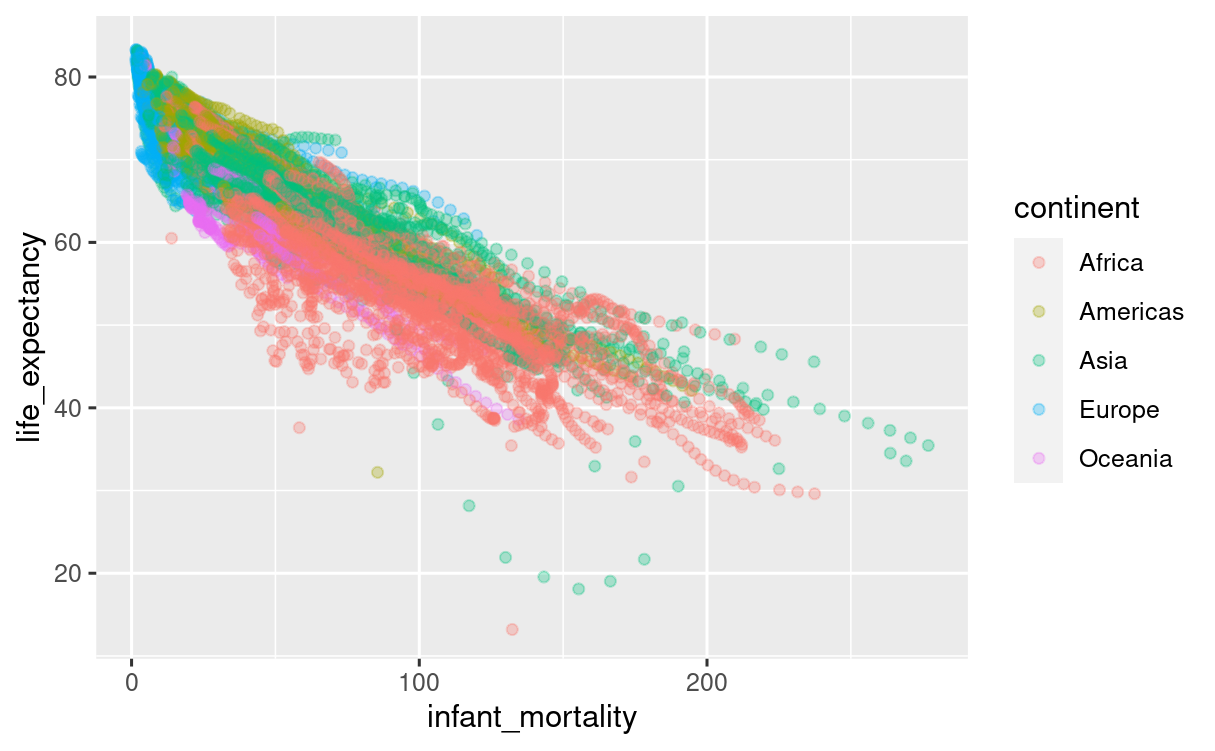
이 스캐터 플롯은 x축, y축이 연속 데이터, 색깔에 이산 데이터를 담아 내었습니다만, 그라데이션 팔레트를 사용하면 색깔에도 연속 데이터를 담아 낼 수 있습니다. 이렇게 세 가지 정보를 담아낸 플롯은 "3차원 데이터" 라고 할 거예요.
아니 그러면 3차원이 넘어가는 걸 보여주고 싶으면 어떡하냐?
여기부터는 필드와 연구 주제, 목적 등에 맞춰서 적당히 데이터에 프로세싱을 해주는 편입니다.
그래도 일차적인 목표는 항상 동일해야 한다고 봐요 : "플롯은 한 눈에 알아먹기 쉬워야 한다."
그래서 보통, 이 포스트를 읽으시는 분들께서 관심 있는 분야의 논문을 아무거나 열어 보시면,
한 플롯에 너무 많은 축이 담겨있는 경우는 잘 없습니다.
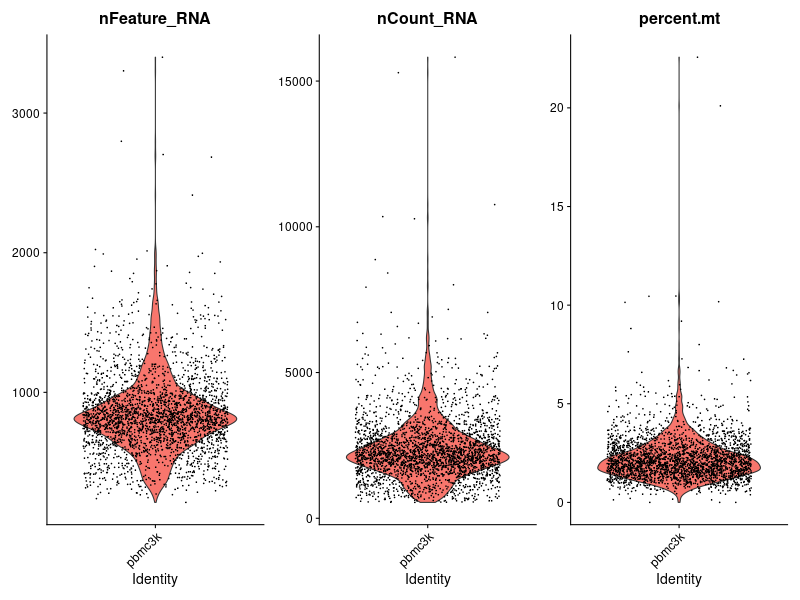
다시 맨 위의 바이올린 플롯을 볼게요.
이 친구의 데이터 형태는, 지난 포스트에서 언급드린 용어로는 큐브 모양, '어레이'의 형태에 가깝습니다.
정확하게는 그보다 훨씬 많은, 다차원적 구조를 지닌 메타 데이터의 형태로 기록되어 있는 데이터입니다.
그러나 여기서는 세 column을 나눠서 각각 플롯을 그렸습니다.
Features, counts, 그리고 미토콘드리아에 의해 간섭이 일어난 비율을 각각의 플롯으로 나눠서 그렸기 때문에, 각각의 분포를 한 눈에 알아보기가 쉽게 되었습니다(피쳐고 카운트고 간섭이고가 뭔 소린지는 관련 랩실에 관심이 있으신 것 아니면 모르셔도 되지 않을까 싶습니다). 쉽게 말해서, 각 플롯에서 설명하고자 하는 변수 외의 데이터 차원은 과감히 생략했다는 것입니다.
차원이고 뭐고 플롯까지 그려가면서 길게 소개해드린 목적은 두 가지 정도가 있습니다.
혹시나 이런 통계가 묻은 그림만 보면 이게 무슨 뜻이지 헤메실 분들께, "그림에서 축이 몇 개인지 확인하고, 그게 연속인지, 이산인지만 먼저 보면 대충 처음 보는 플롯 형태라 해도 이해가 불가능 하지는 않을 것이다" 라는 것,
그리고 이후 기초 통계학을 넘어서 Regression analysis(회귀 분석, 나중에 따로 포스트로 소개해 드리겠지만 'normality(정규성)' 를 가정합니다), 더 나아가 robust statistics(대충, 데이터가 normal이 아닌 경우에 쓰는 분석 방법) 등을 보실 일이 분명히 있으실텐데, 그 때 이 데이터의 '차원(dimension)' 이라는 게 꽤나 중요하게 논의 된다는 것, 정도 입니다.
말이 나온 김에 PCA(주 성분 분석)라는, 바이오 논문에서 자주 보이는 분석 방법의 컨셉 까지만 간단하게 소개해 드리는 것도 좋겠어요.
2. PCA (Principal Component Analysis), 간단히.
사실 이걸 조금 더 명확하게 소개해 드리려면 회귀 분석에 대한 내용이 먼저 선행되어야 할 것 같긴 한데, 모르겠고 그냥 일단 들이박아 보겠습니다.
보통 바이오처럼 실험 데이터를 많이 쓰는 연구에서는 데이터 분석을 통해 '요인'을 찾는 걸 목표로 설정하는 편입니다.
예를 들어 Single-cell RNA sequencing(이하 SC seq)는 PCA를 통해 비슷한 타입의 셀을 찾아내려고 해요('클러스터링' 이라고 합니다).
먼저 그럼 PCA를 언제, 왜 쓰는지 보도록 하겠습니다.
사영(Projection) 이라는 개념은 데이터 차원의 축소에 자주 쓰이는 기법입니다.
네, 저희가 고등학교에서 배운 그것 맞습니다.
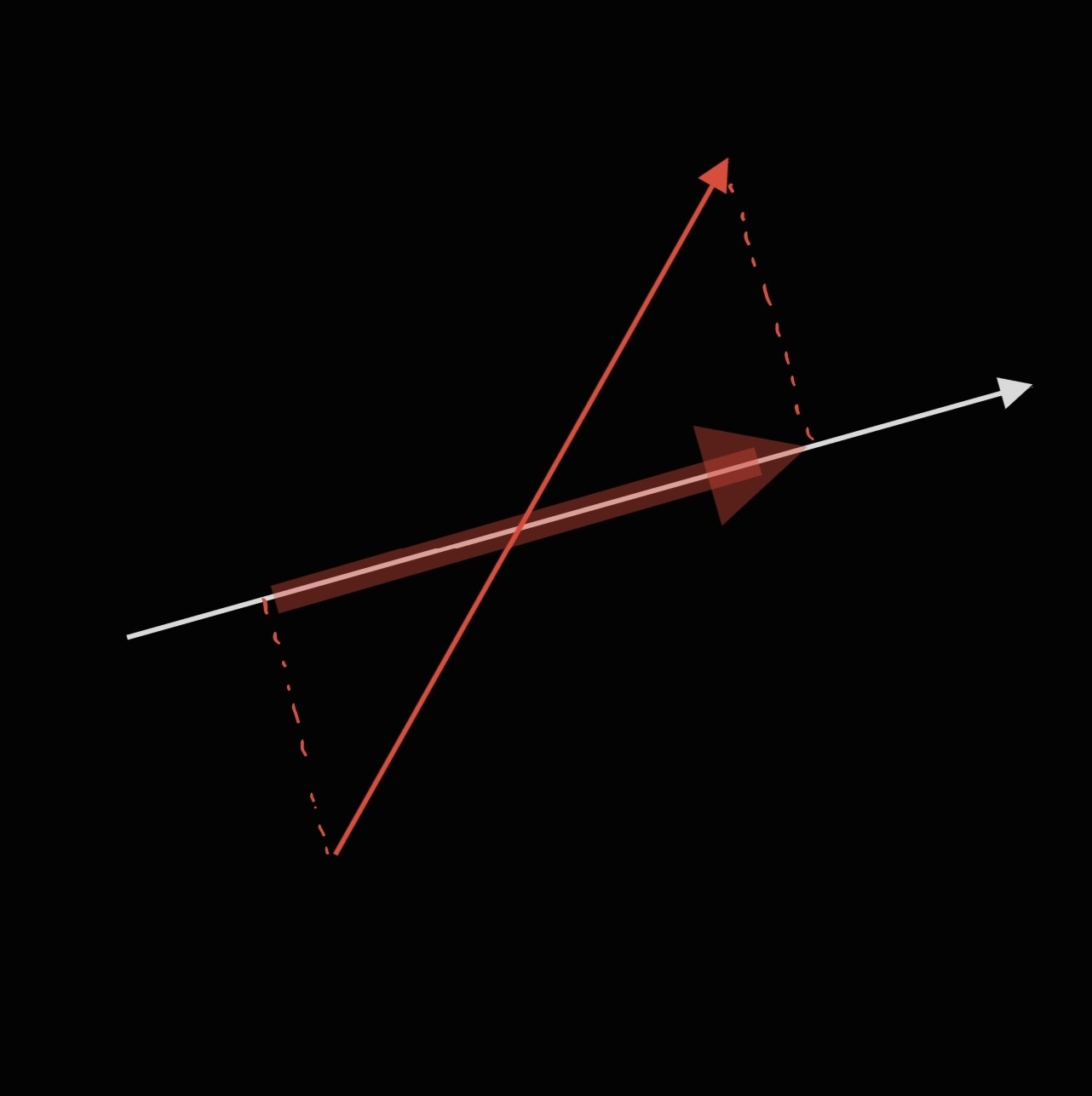
고등학교때 했던 것 만큼 수학적으로 벡터를 막 계산할 건 없고, 대충 이게 어떤 식으로 응용되는지 보겠습니다.
"n차원 공간" 이라는 건, n개의 서로 다른 수직인 축이 이루는 공간을 말합니다.
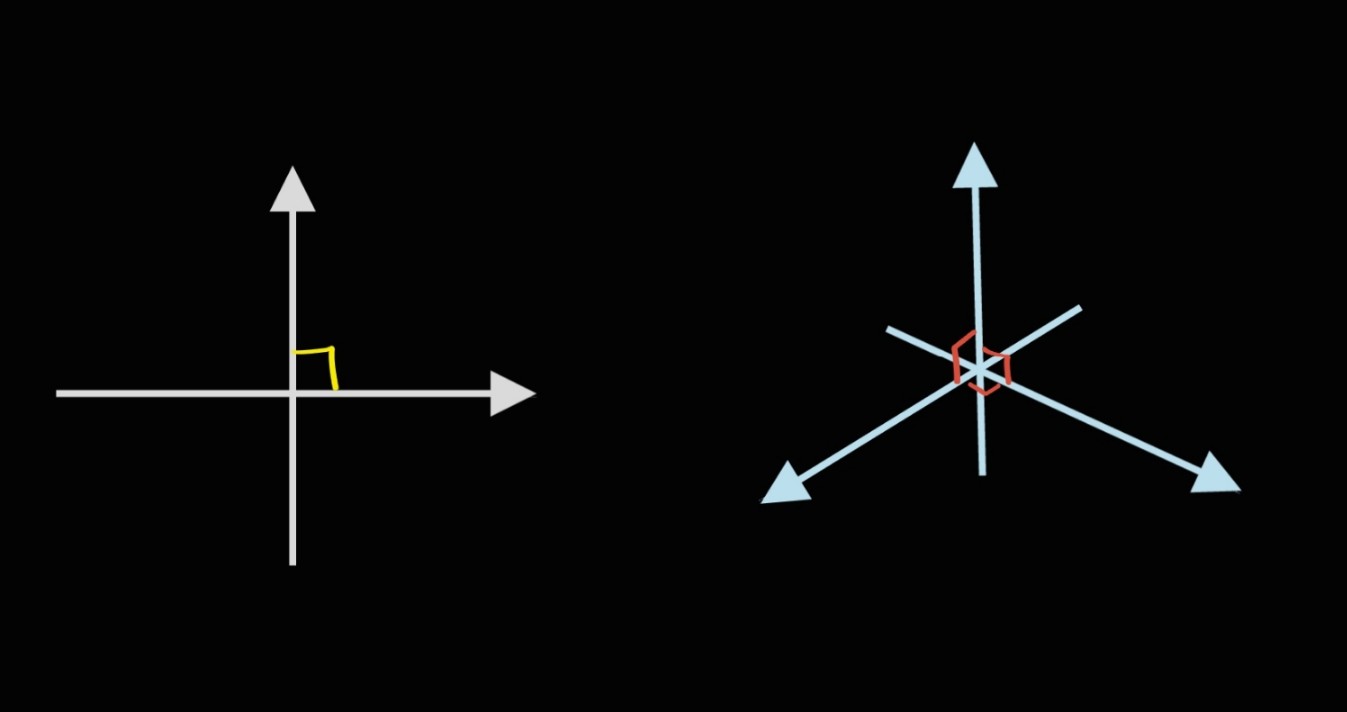
보시다시피 2차원 공간은 두 개의 직선이 수직을 이뤄 만든 공간을 말하고, 그 공간의 모양은 평면입니다.
3차원 공간은 세 개의 직선이 수직을 이뤄 만든 공간을 말합니다.
이런 개념으로 생각해 보면, 어떻게 생겼는지 알기는 힘들지만 4차원, 5차원, ... , 100차원 공간도 뭐 있을 수는 있겠구나, 상상해 볼 수 있을 거예요.
이걸 데이터에 적용해 보겠습니다.
흔히 '데이터 분석' 이라는 건, 데이터의 분포(데이터가 흩뿌려진 모양)를 보고 요인을 찾아내는 과정을 이야기합니다.
2차원 데이터는 2차원 공간에,

이렇게 뿌려져 있을 거고, 적당히 파란색 투명한 선이 데이터의 분포를 설명하는 요인 식이라고 말할 수 있을 거예요.
관련해서는 나중에 회귀분석으로 간단히 소개해 드리는 포스트를 따로 작성하겠습니다.
아무튼, 비슷하게 3차원 데이터는

이렇게 3차원 공간에 흩뿌려져 있을 겁니다. 아 똑바로 좀 그리지 알아보지도 못하겠구만 이게 뭐야.
그렇죠, 데이터의 분포를 알아보기 힘들었던 저는,
3차원 데이터를 이렇게 2차원 평면으로 사영시킨 후에, 위에서 내려다 보았습니다. 그랬더니,
이제서야 저 같은 바보도 알아볼 수 있는 그런 그림이 되었네요!
이런 "차원 축소"는 복잡한 데이터의 분석에서 자주 고려하는 과정입니다. 왜냐면,
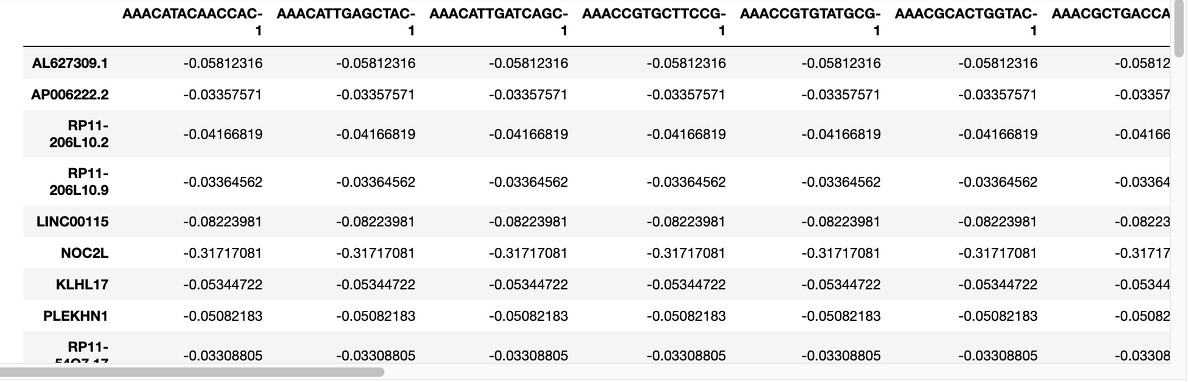
이 데이터는 1만 4천여 개의 변수를 적당히 만져서 2천개로 줄인 데이터입니다.
이 데이터를 좌표 공간에서 분포를 확인하려면 축이 2000개인 공간을 먼저 그려야 하는데, 일단 저는 그럴 능력이 안 됩니다.
또 그리지 않고 계산을 한다 쳐도, 축이 2000개 라는 건 계산의 기준 선이 2000개라는 뜻이라, 계산 양이 어마어마해 질 것 같아요.
이런 문제들을 피하기 위해, 이런 고차원 데이터는 차원을 낮춘 뒤에 분석을 진행하는 편입니다.
그런데 이 때 문제가 생깁니다.
데이터의 차원을 낮추면 원래 데이터에서 정보가 사라지는 경우가 있습니다.
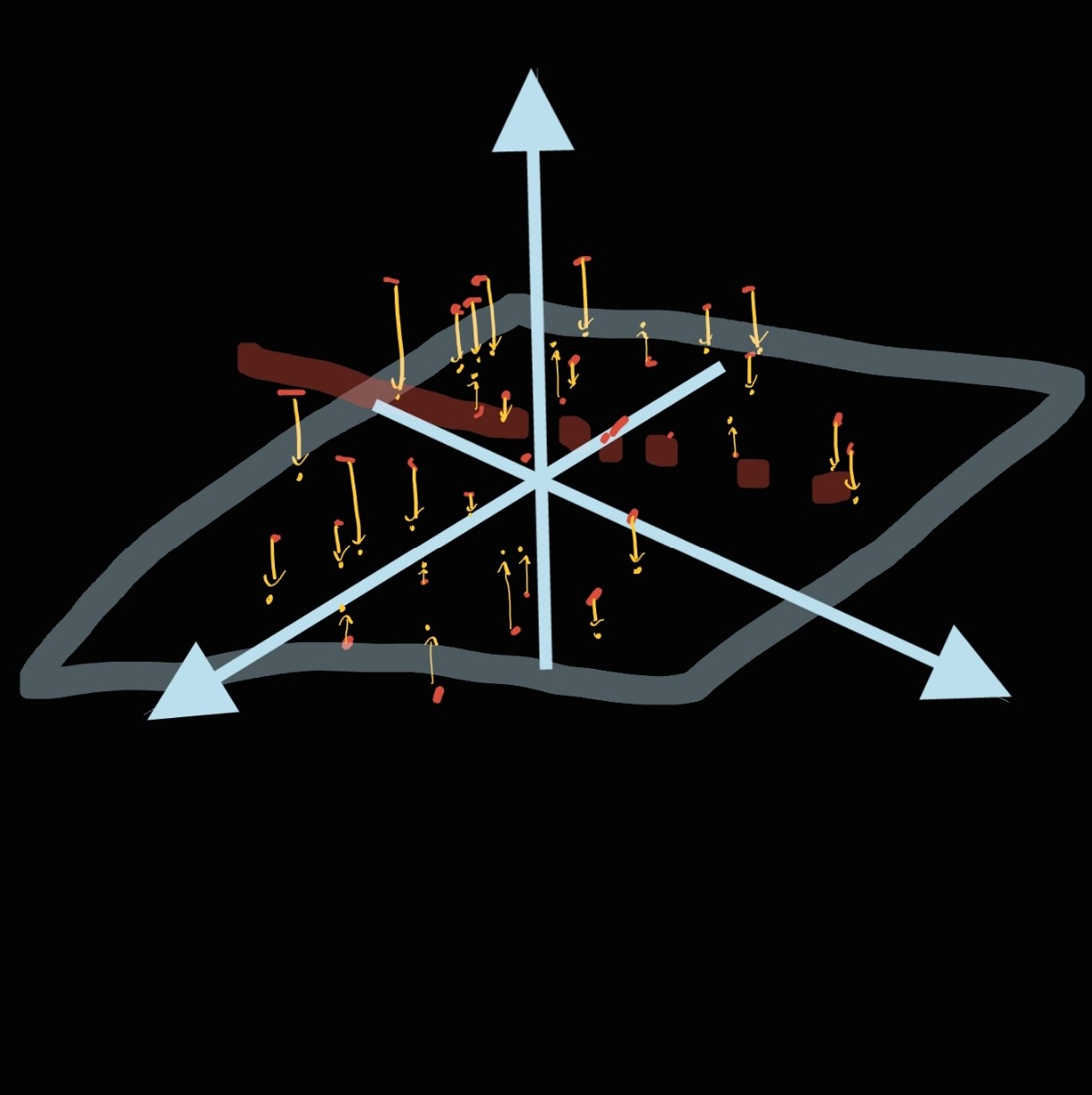
예를 들어, 위에서 그려드렸던 3차원 데이터의 X, Y, Z축이 각각 "년도", "생산량", "판매량" 을 각각 의미한다고 해 볼게요.
저는 이 점들을 xy 평면으로 프로젝션 시켰습니다. 그럼 이때 나오는 데이터는,

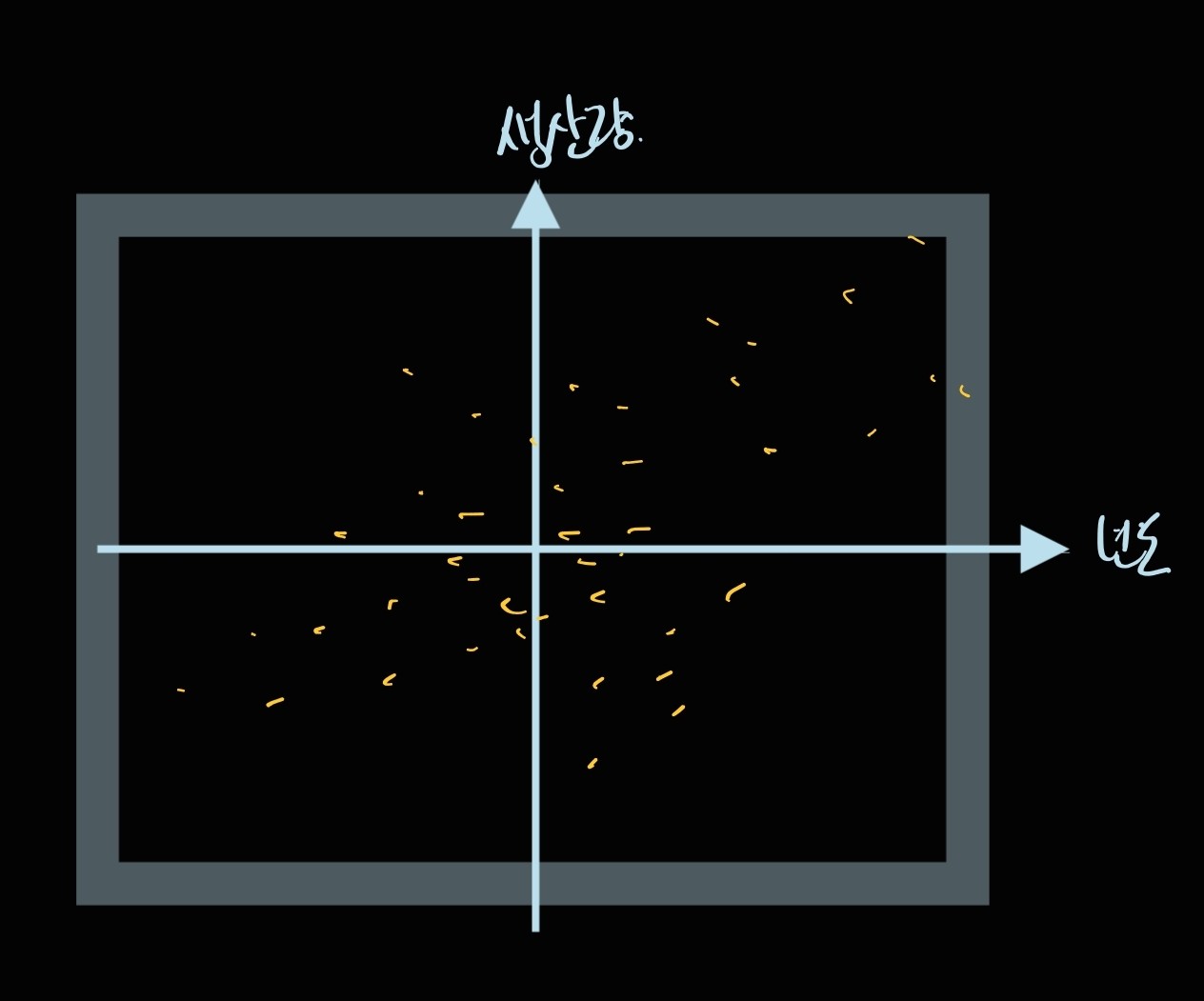
분포를 한 눈에 보기는 쉽지만, 분포에서 "판매량"에 관한 정보가 사라져 버렸습니다.
즉, 뭔가 유의미한 변수를 임의로 제거해 버린 꼴이라, 아마도 원래 데이터에서 얻을 수 있었던 유의미한 결론을 놓치게 될 거예요.
그치만 차원을 줄이지 않고 원래 데이터로 계산할 용기는 없는데. 컴퓨터가 버텨줄 것 같지도 않고.
그렇다면 데이터의 손상이 최대한 일어나지 않도록 새로운 축을 만들어서 그 방향으로 프로젝션 시키면, 완벽하진 않더라도 나름대로 비슷한 결론을 얻을 수 있지 않을까요?
아래와 같은 느낌입니다.
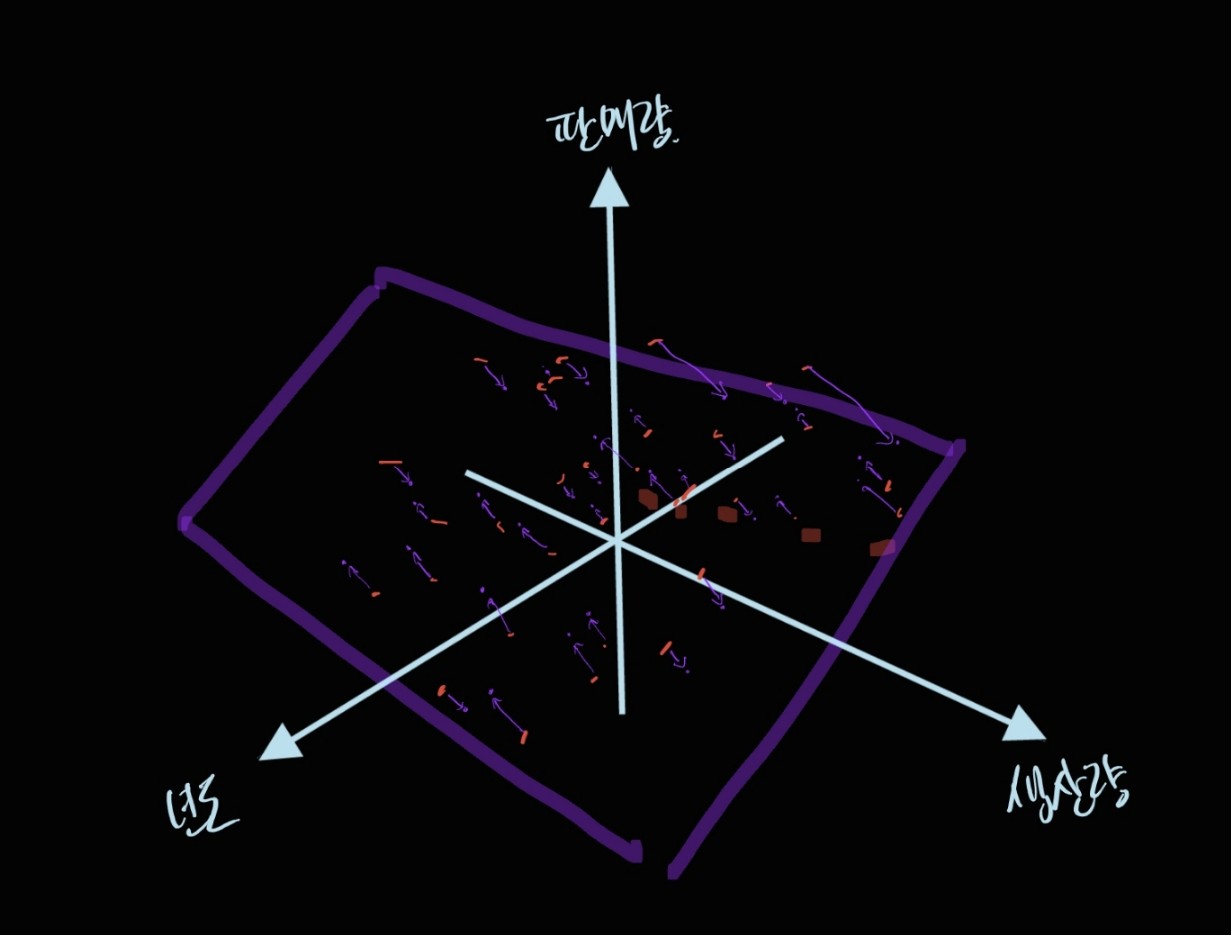
이렇게 새로운 보라색 평면을 적당히 만들어 내고, 그 보라색 평면으로 프로젝션 된 각 점들이 원래 데이터의 (대충)80~90퍼센트 정도의 정보를 보존하고 있다면, 뭐 제 생각엔 이 경우에서는 나쁘지 않을 것 같습니다. 아마도 원래의 결론과 비슷한 결론을 내릴 수 있지 않을까요?
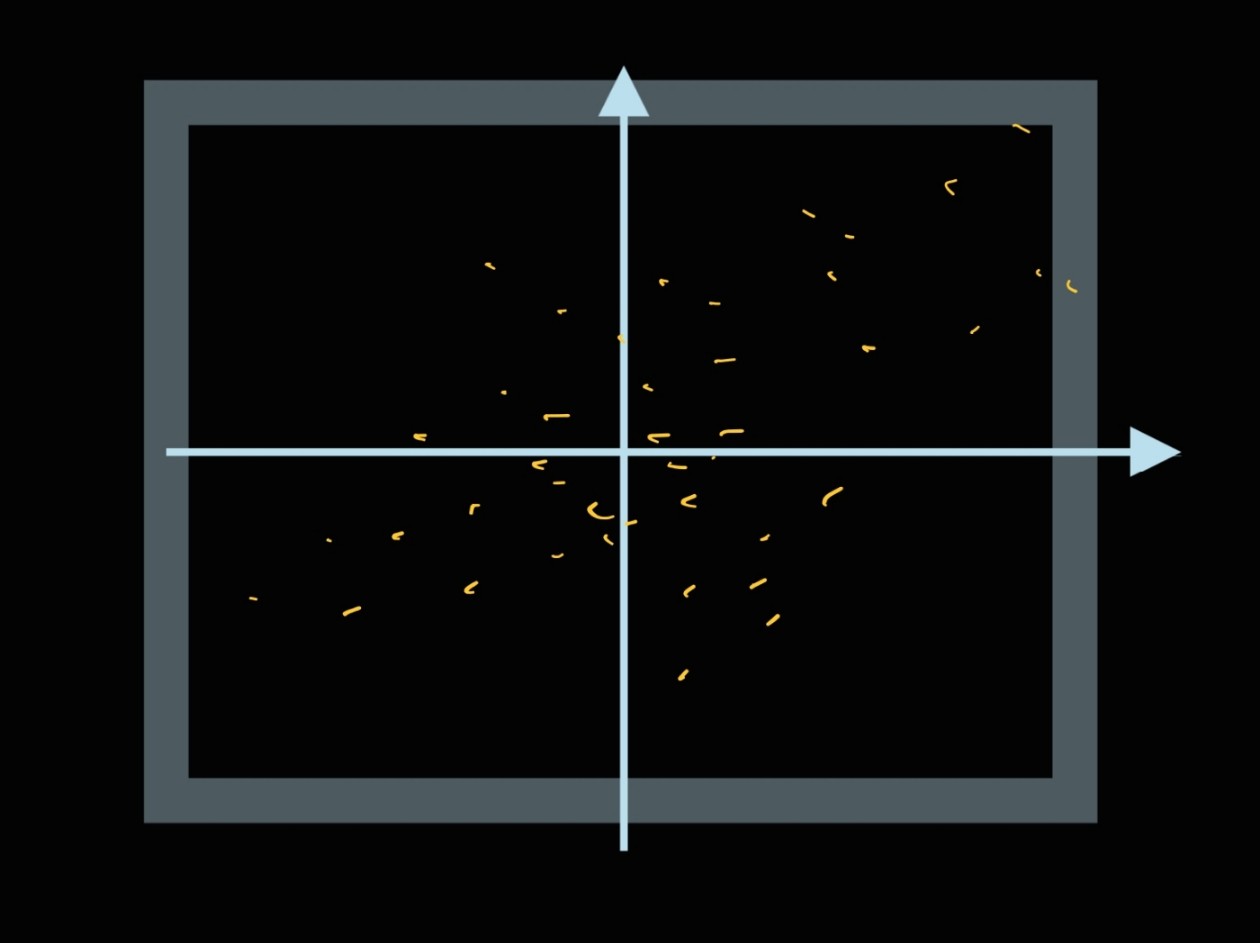
그래서 보라색 평면을 위에서 내려다 보면 아래와 같은 분포를 얻어볼 수 있겠는데요,
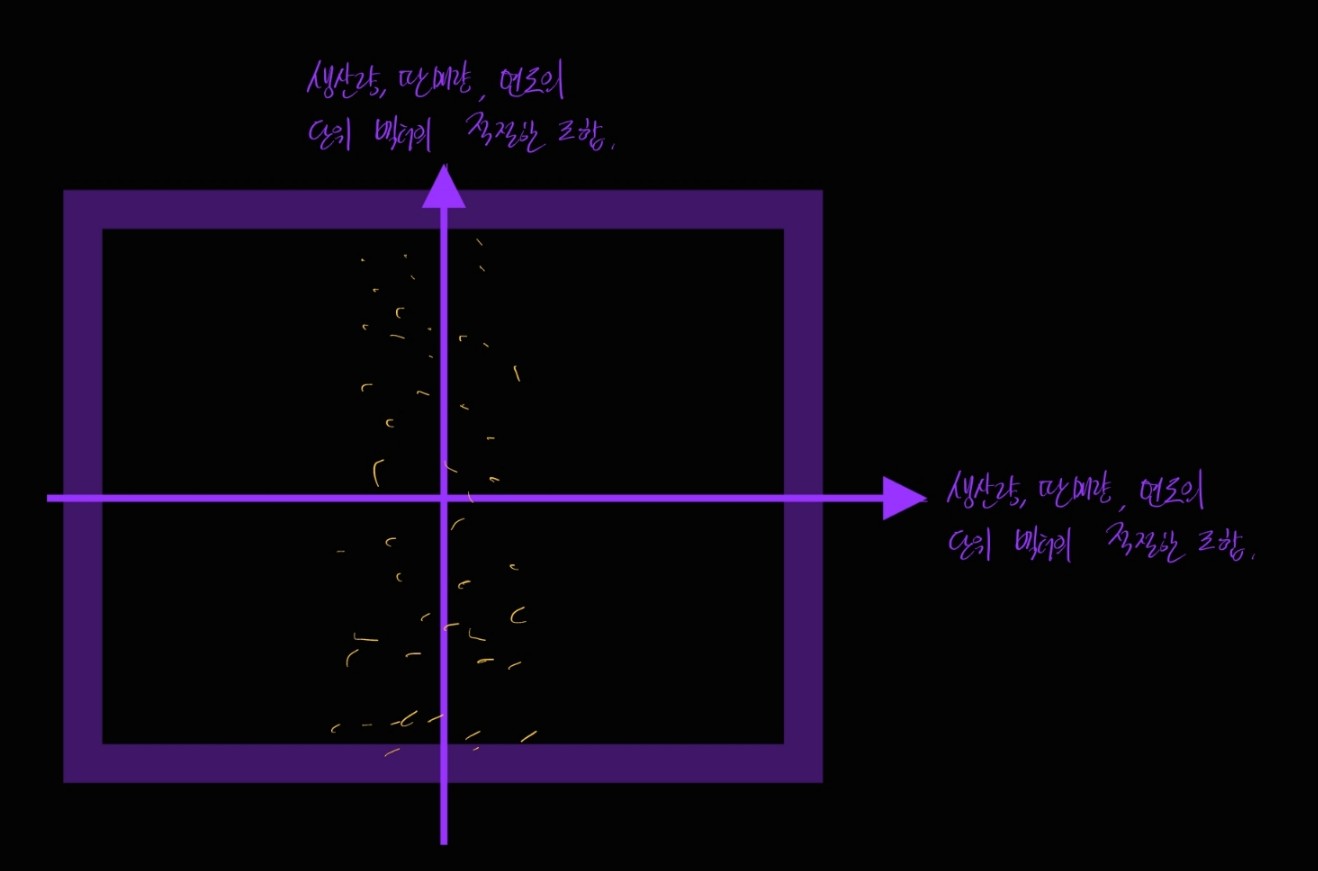
새로 만들어진 이 보라색 평면의 축은, 원래 데이터의 축인 '생산량', '판매량', '년도' 를 적당히 더해서 만들었습니다.
그러니까,
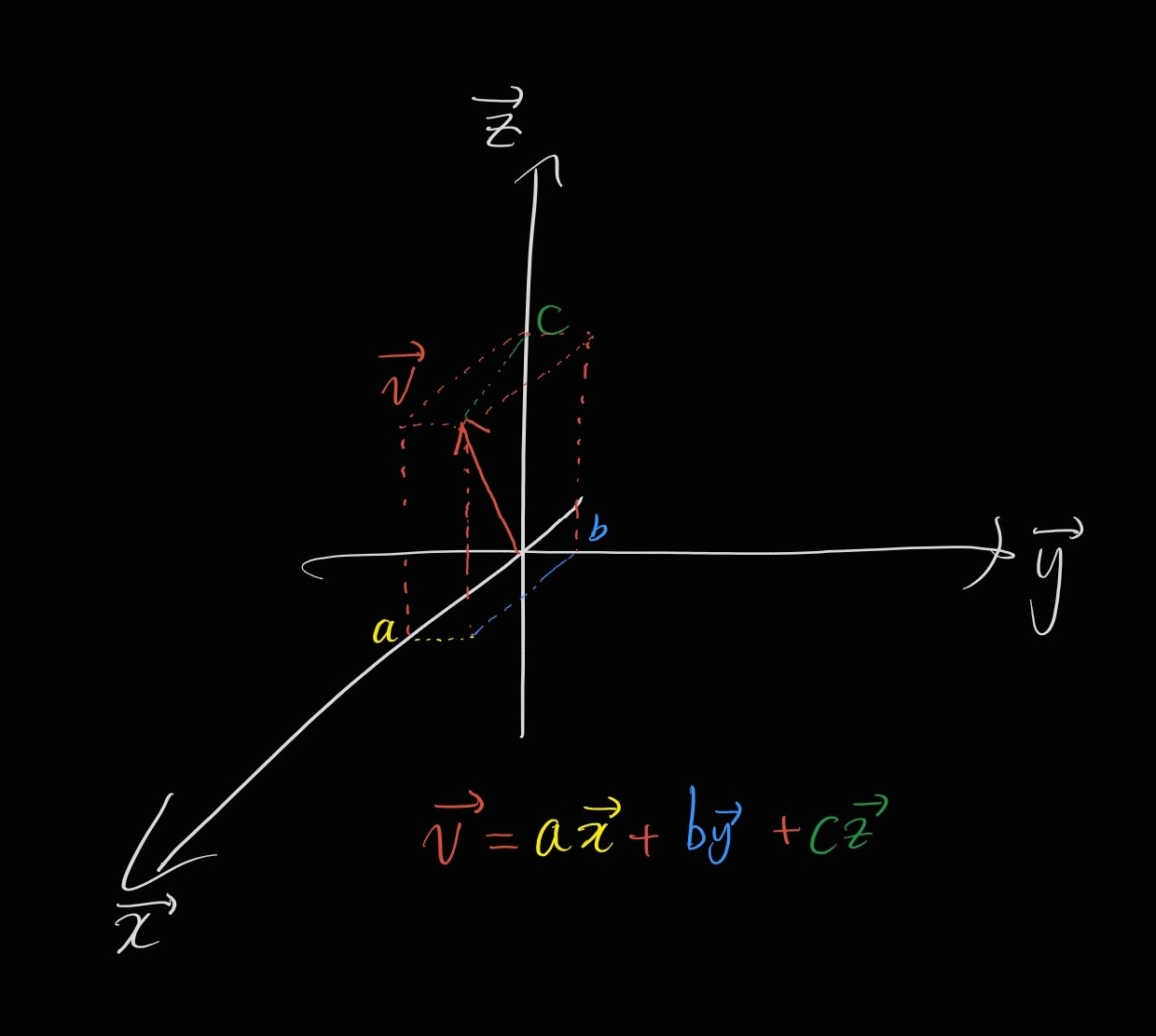
벡터 공간(여기서는 3차원 벡터를 예시로 쓰기 때문에, 그냥 좌표 공간을 의미합니다)의 임의의 벡터 v는 그 좌표 공간 안의 다른 벡터들의 합으로 표현할 수 있어요.
이 그림에서 v가 새로 만든 보라색 평면의 축에 해당하고(이 벡터를 Principal Component, 한국어로는 주 성분, 줄여서 PC라고 부릅니다), x, y, z가 원래 데이터의 변수인 생산량, 판매량, 년도에 해당한다고 보시면 이해가 조금 되실 것 같습니다.
아니 그럼 그 새로운 축들을 어떻게 적당히 잡는데?
여기부터는 수학의 영역입니다(선형대수의 eignevalue와 eigenvector 같은 내용에서부터 출발해요). 기초 통계만을 다루는 제 포스트의 수준에서는 논의하기 힘들고, 그냥 대단하신 분들이 원래 데이터의 정보를 적당히 보존하도록 새로운 축을 계산하는 분석 방법을 만들었다! 정도 까지만 챙겨가시면 될 것 같아요.
마지막으로 위에서 보여 드린 2000차원 데이터를 이런 식으로 변형하면,
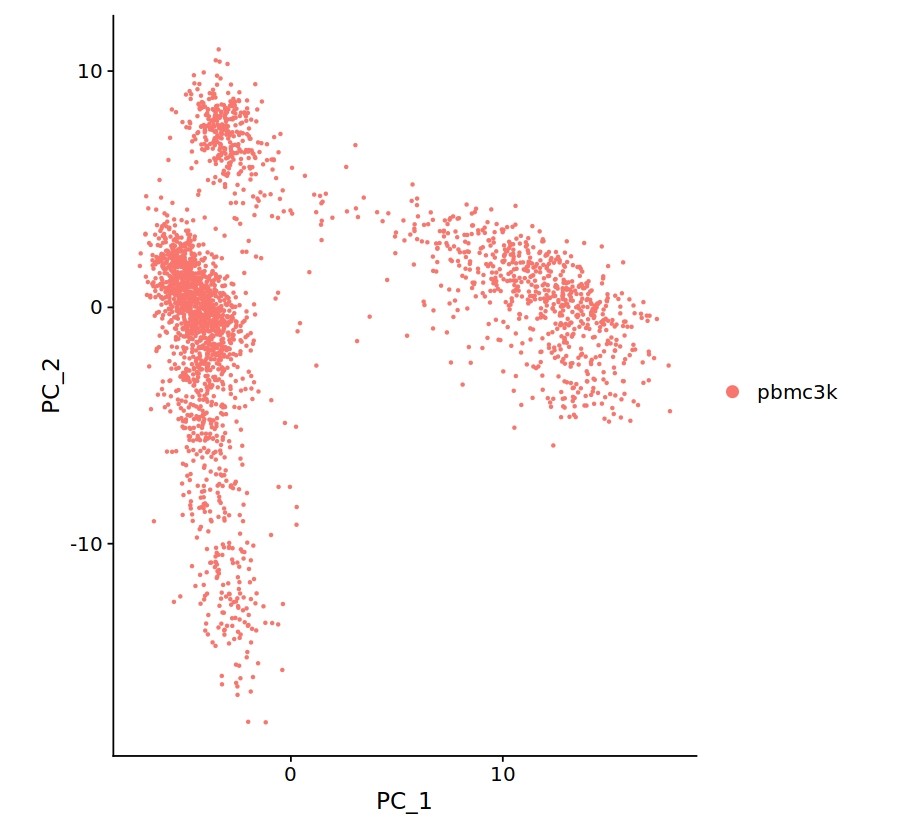
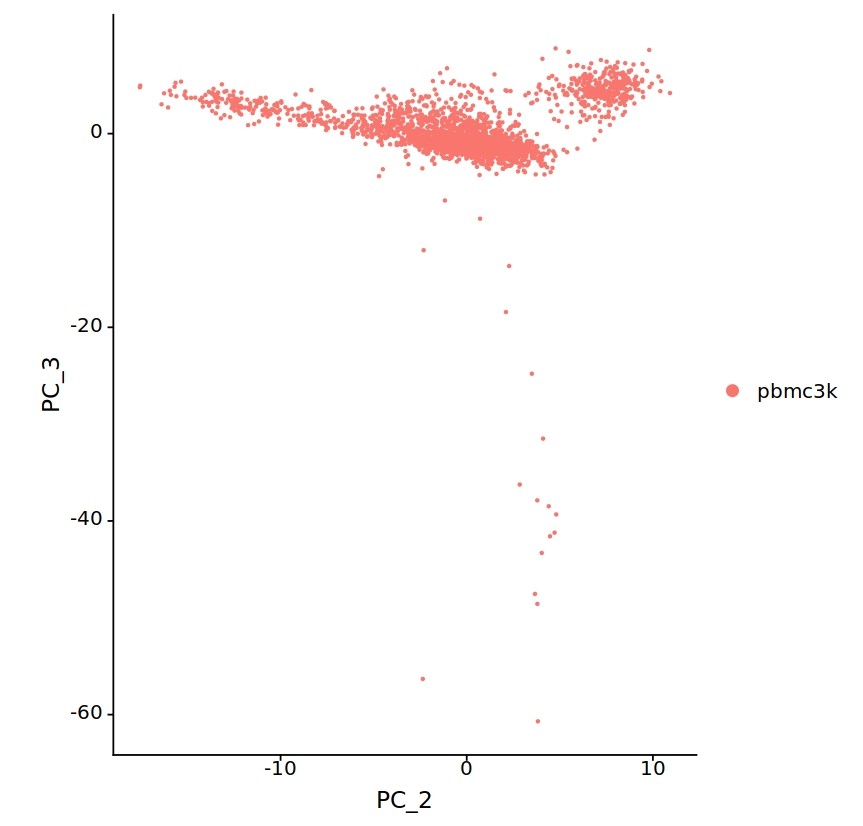
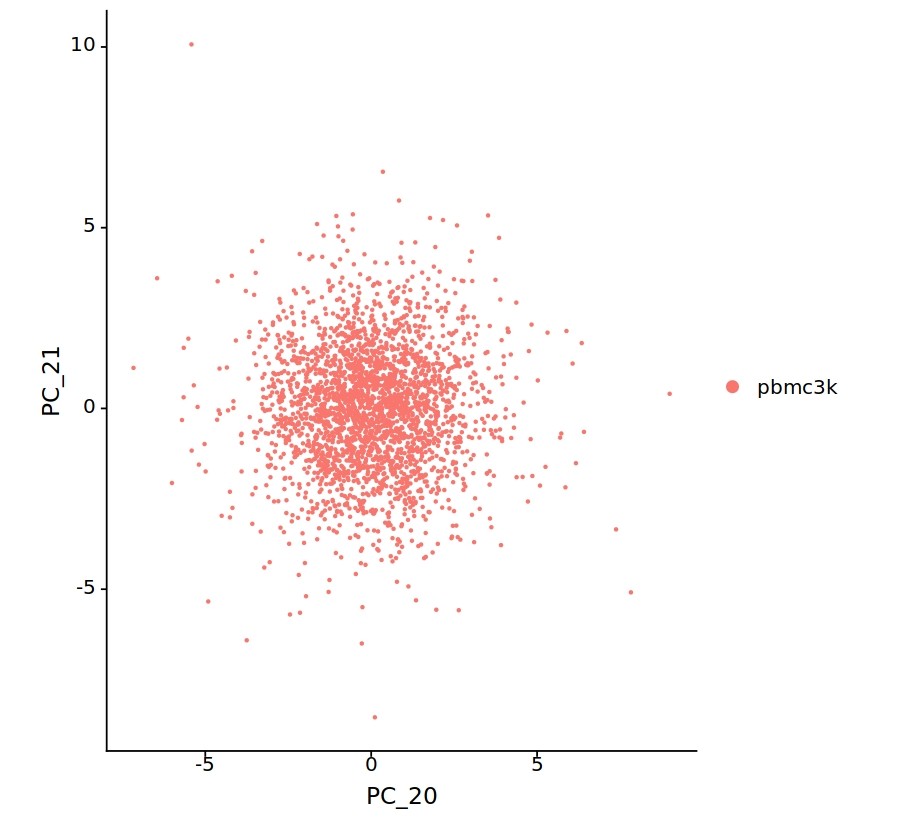
이렇게 임의로 만든 축을 기준으로 데이터의 분포를 확인할 수 있고, 이걸 바탕으로 덜 계산하면서 적당한 요인을 찾는 분석을 진행할 수 있을 것 같습니다(2000차원을 몇십개의 차원으로 줄였기 때문에, 역시 한 번에 분포를 확인하기는 어렵지만 그들 중 축을 두 개씩 선택해서 평면으로 프로젝션 시킨 그림들입니다).
사실 당초 계획에는 PCA 관련한 내용을 넣을 예정은 없었습니다만, 최근 들어 주변 지인들의 문의가 빗발치고 있어(?) 살짝 개념만 넣어 보았습니다. 적당한 설명이 되었는지는 모르겠습니다. 한번에 너무 많은 내용을 다루기엔 쉽지 않아서, 실제로 사용 / 응용해보고 싶으신 분들은 적당한 강의를 찾아 들어 보시거나 구글링으로 좋은 자료를 구해 보시는 게 좋을 것 같아요.
다음 시간에는 다시 기초통계학 내용으로 돌아와서, 드디어 "확률 분포"라는 게 뭔지 소개하는 내용으로 준비해 보겠습니다.
'Z-bio stat > Z-기초통계학' 카테고리의 다른 글
| [Z-bio Stat] 8. Bernoulli Trial: Binomial, Geometric, Hypergeometric, Negative Binomial Distribution (0) | 2023.01.10 |
|---|---|
| [Z-bio Stat] 7. 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset) 이다 (0) | 2023.01.01 |
| [Z-bio Stat] 5. 선형대수 표시법: Matrix를 왜 쓰는가? (0) | 2022.12.22 |
| [Z-Bio Stat] 4. 확률 함수 : cmf / cdf / pmf / pdf (0) | 2022.11.28 |
| [Z-Bio Stat] 3. 샘플링(Sampling)과 확률 변수(Ramdom Variable) (0) | 2022.11.20 |



