
- 확률(Probability)의 재정의
- 통계와 통계량(Statistics)
- 샘플링(Sampling)과 확률 변수(Random Variable)
- 확률 함수: cmf / cdf / pmf / pdf
- 선형대수 표시법: Matrix를 왜 쓰는가?
- 데이터와 차원의 표현: 정보의 압축
- 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset)이다
- Bernoulli Trial: Binomial, Geometric, Hypergeometric, Negative binomial distribution
- Poisson Process: Exponential, Gamma, Beta distribution
- 추정(Inference): 귀무가설과 대립가설, 유의 수준과 p-value, 신뢰구간(CI)
- 추정(Inference) (2): Pivotal quantity, Student-t, Chi-square, F test and ANOVA table
- Experiment prediction: 회귀분석(Regression Analysis)의 가정(assumptions)과 아이디어
- Appendix
종강 시즌을 맞아 후다닥 시리즈를 끝내버리려고 출근하지 않는 날 동안 스퍼트를 내는 돌문어같은 자라입니다.
이번 포스트부터 세 편 정도는 '확률 분포' 를, 그 뒤로 세 편 정도는 '통계 추정'에 관한 내용을 소개해 드릴 계획입니다.
그리고 이 분포에 관한 이야기는 이전 내용까지는 달리, 크게 어렵지 않으면서도 당장 어디가서 아는 척 하기 좋은 영양가있는 내용들이 될 것 같아요.
1. 확률 분포?
그치만 사실 확률 분포라는 개념 자체가 썩 그렇게 직관적이지는 않습니다.
저번 포스트에서 열심히 보여 드렸던 데이터의 "분포", 그리고 지금은 확률 "분포", 같은 단어를 사용해서 그런가 저는 처음에 좀 혼동했던 것 같아요.
확률 분포란, '확률의 분포'를 말합니다.
그냥 어떤 확률 변수의 pdf, 혹은 pmf를 이야기해요.
pdf를 아무거나 그려 놓고 무슨 뜻인지 다시 한 번 짚어 보겠습니다.

확률 변수 X의 확률 함수 \(f_X(x)\)가 이렇게 생겼다고 할게요. 그러면 이것 자체가 확률 분포입니다.
다시 말해서, 이전에 보여드린 적 있는 노테이션인데,
$$ X \sim D(\theta) $$
이렇게 쓸 수 있다는 거예요.
그런데 여기서 \(D\)와 \(\theta\) 가 무엇을 의미하는지는 아무도 모릅니다. 심지어 그림을 그린 저도요. 굳이 찾아야 할 이유도 딱히 없구요 (음, 몰라서 \(D\)와 \(\theta\) 라는 기호를 썼다, 라는 표현이 맞을 것 같습니다).
다만 여러 분야들의 연구 상황에서 자주 쓰이는 특정한 형태의 확률 함수들에는 특별한 이름을 붙여 두고 필요할 때 찾아 쓰고 있습니다.
정규분포\( (N(\mu , \sigma^2) \)나 포아송 분포\( Poisson(\lambda) \) 등이 그런 예시들입니다.
1-1. 정규 분포 (Normal Distribution)
확률 분포를 어떤 식으로 바라보면 좋을지 소개해 드리려면, 예시로 들만한 적당한 분포가 필요할 것 같습니다.
우리 모두가 다 모양 정도는 알고 있는 정규 분포로 소개해 드릴게요.
확률 분포는 확률 함수와 같은 말이라고 말씀드렸는데,
우리는 아래와 같이 생긴 pdf를 갖는 확률 변수를, '평균이 \( \mu \)이고 분산이 \(\sigma^2\)인 정규 분포를 따른다' 라고 이야기하기로 했습니다 :
$$ f_X(x)=\frac{1}{\sqrt{2 \pi \sigma^2}}exp\{-\frac{(x- \mu)^2}{2 \sigma^2}\} $$
그리고 그 MGF는
$$ M_X(t)=exp(\mu t + \frac{\sigma^2 t^2}{2}) $$
( \(exp(n)=e^n \)이고, MGF같은 경우는 \(E(e^{tx}) \) 를 잘 정리하면 위와 같은 식을 얻을 수 있습니다)
그러니까, 아래 친구들은 다 정규분포입니다.
$$ f_Y(y)=\frac{1}{\sqrt{2\pi}} e^{-\frac{y^2}{2}} \quad \Rightarrow \quad Y \sim N(0, 1) $$
$$ f_U(u)=e^{-\pi (u-e)^2} \quad \Rightarrow \quad U \sim N(e, \frac{1}{2\pi}) $$
$$ f_V(v)=\frac{1}{\sqrt{\pi}}e^{-(v-1)^2} \quad \Rightarrow \quad V \sim N(1, \frac{1}{2}) $$
$$ \vdots $$
저번에도 소개드렸지만, 정규분포는 평균과 분산이라는 두 가지의 파라미터로 설명합니다.
정규분포의 평균은 그 분포의 위치를 설정하는 Location parameter 이구요,
분산은 정규분포가 퍼져있는 정도를 말해주는 Scale parameter 입니다.
위의 Y, U, V 세 확률 변수를 그림으로 그리면 아래와 같습니다.
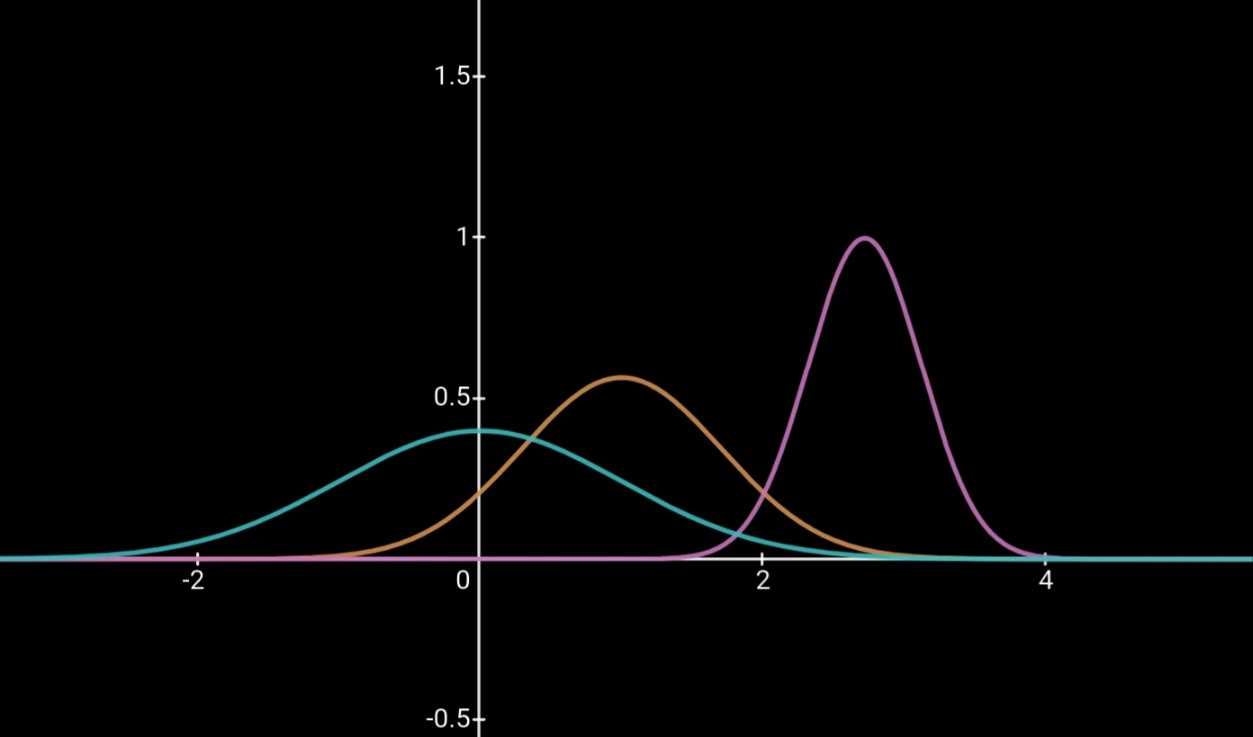
스케일 파라미터인 분산이 작을 수록 더욱 좁고 뾰족한 함수가 그려지네요.
그럼 정규분포의 식은 어떻게 유도되었을까요? 하늘에서 뚝 떨어진 걸까요?
정규분포는 아래의 특징을 갖는 확률 분포를 가정합니다. 그러니까, 똑똑하신 분들께서 아래의 특징들을 갖는 함수 식을 만들고 싶었던 거예요.
아직 정규 분포의 확률 식을 모르는 상태라고 쳐요.
정규 분포의 확률 함수를 \(f_X(x)\)라고 쓸 때,
- 일단 확률 함수니까, 모든 실수 구간에 대해 확률 합이 1입니다. 즉,
$$ \int_{-\infty}^{\infty}f_X(x)\;dx\;=\;1 $$
- 또한 정규 분포는 평균에 대해 대칭입니다. 즉,
$$ f_X(\mu - \alpha) = f_X(\mu + \alpha) $$
- 그리고 정규 분포는 평균에서 최댓값을 갖습니다.
$$ max\{f_X(x)\} = f_X(\mu) $$
평균과 분산이라는 파라미터를 쓰면서 위의 성질을 갖도록 식을 유도하면, 앞에서 저희가 봤던 정규분포의 식을 얻을 수 있습니다.
자세한 과정은 완전히 수리통계학적 내용이라 생략하겠습니다. 극좌표 등 고등학교 수준을 넘어서는 수학 테크닉이 필요하기도 하고, 만들어진 분포를 쓰기만 하는 저희가 굳이 굳이 알아야 할 필요가 있...을까요?
+.
참고로, 이와 비슷하지만 절댓값을 쓰는 분포가 있습니다.
처음 보셨을 텐데, 라플라스 분포(Laplace distribution)라는 게 있어요 :
$$ f_X(x)=\frac{1}{2 \sigma}e^{-\frac{|x-\mu|}{\sigma}}\;-\infty<x<\infty \quad X \sim DE(\mu, \sigma) $$
DE는 Double exponential의 약어이고, 이는 라플라스 분포의 또 다른 이름입니다.
정규분포와 비슷하게 생겼지만, 평균 근처에서 뾰족한 모양을 갖고 있어요.
정규 분포와 컨셉이 겹쳐서 딱히 자주 접하게 될 분포는 아닐 것 같구요, 게다가 의외로 '라플라스 변환' 과도 전혀 관련이 없습니다. 그러니까 진짜 그냥 이런 것도 존재는 하는구나, 정도만 챙기셔도 될 것 같습니다.
2. 시뮬레이션 (Simulation)
그럼 이 정규 분포를 들고, 확률 분포가 어떤 의미를 갖는지 들여다 보도록 하겠습니다.
확률 분포의 의미를 가장 직관적으로 확인하는 방법으로는 시뮬레이션이 있습니다.
먼저, 시뮬레이션이라는 건 통계를 다룰 때 많이 쓰는 기술입니다. 실험을 통해 확률 함수의 모양을 눈으로 볼 수 있게 해주기 때문이예요.
방법 자체도 생각보다 원시적인데, 그냥 코딩으로 실험 조건을 걸어준 뒤 반복 시행을 많이 해주면 됩니다. 천천히 보여 드릴게요.
우리 확률 변수가 노말 제로원(\( N(0, 1) \) )을 따른다고 해보겠습니다.
물론 보통은 전체 중 일부에 해당하는 샘플, 그러니까 데이터를 보고 전체 확률 변수가 어떤 분포를 따르는지 찾아내는 과정이 보통 우리 분석의 목적인데요,
일단 그걸 하려면, 확률 분포 안에서 확률 변수가 어떤 움직임을 보이는지 알고 있으면 좋을 것 같습니다.
그래서 "우리가 전지전능한 존재라서 모집단의 분포를 알고 있다" 라는, 현실에서 절대 불가능한 가정을 하고서 들어가 보겠습니다.
노말제로원의 확률 분포는 아래와 같습니다.

그럼 R을 통해, 딱 한 개짜리 샘플을 만드는 샘플링을 해볼게요.
아마 음의 무한대부터 양의 무한대 사이 실수 중 어떤 수든 랜덤하게 나올 겁니다.
그리고, 아마도 0에서 별로 멀지 않은 숫자가 나올 것 같습니다. 확률 밀도 함수를 보니 평균인 0 근처에서 밀도가 크거든요!
rnorm(1)
#> -0.8543452
역시 평균인 0에서 별로 멀지 않은 숫자가 뽑혔습니다.
자 그럼 반대로, 저 -.854...어쩌고 하는 숫자만 보고서, 이 X가 어떤 분포를 따르는지 알 수 있을까요?
절대 모를 겁니다. 정규분포 뿐만 아니라 어떤 확률 분포에서든 딱 하나의 데이터만 보고는 얘가 어떤 확률 분포를 따르는지 알 수가 없을 거예요.
그럼 확률 분포, 즉 확률 변수의 함숫값은 어떤 의미가 있을까요?
노말 제로원을 따르는 확률 변수를 반복해서 뽑고 그 빈도를 출력해주는 시뮬레이팅 함수를 간단히 짜보고, 돌려볼게요.
# N에 반복 시행 수를 넣으면, 그 횟수만큼 크기가 한 개인 샘플을 만들고 결과를 히스토그램으로 표시합니다.
zbio7=function(N){
p=rnorm(N)
hist(p, freq=F, main = paste("N =", N))
}
일단 10번 정도 반복해 볼게요. 숫자 하나를 10번 뽑겠습니다.
zbio7(10)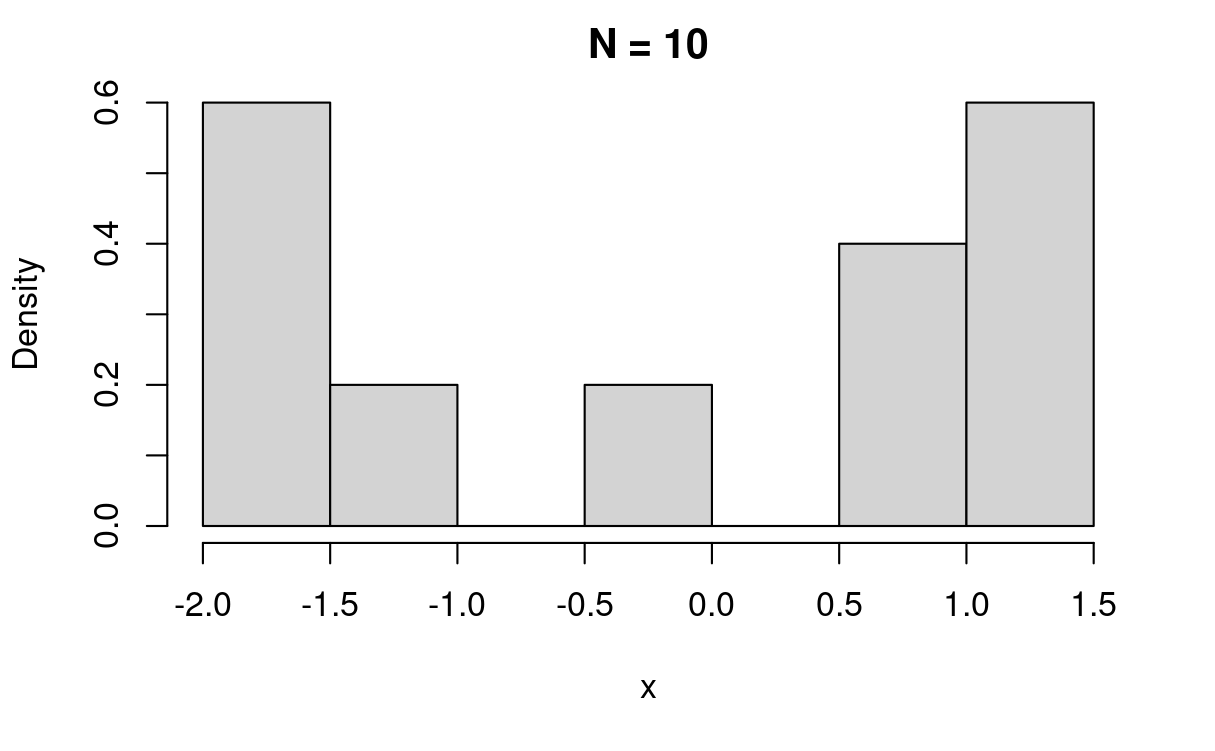
(이 결과는 코드를 돌릴 때마다 매번 다르게 나오는 결과이긴 합니다. 직사각형 막대의 가로 축은 뽑힌 숫자가 포함된 구간을, 세로 축은 그 구간의 비율을 나타냅니다)
뭔가 별로 의미 없어 보이는 모양이긴 하지만, 일단 반복 수를 계속 늘려가 보면,
zbio7(100)
zbio7(1000)
zbio7(10000)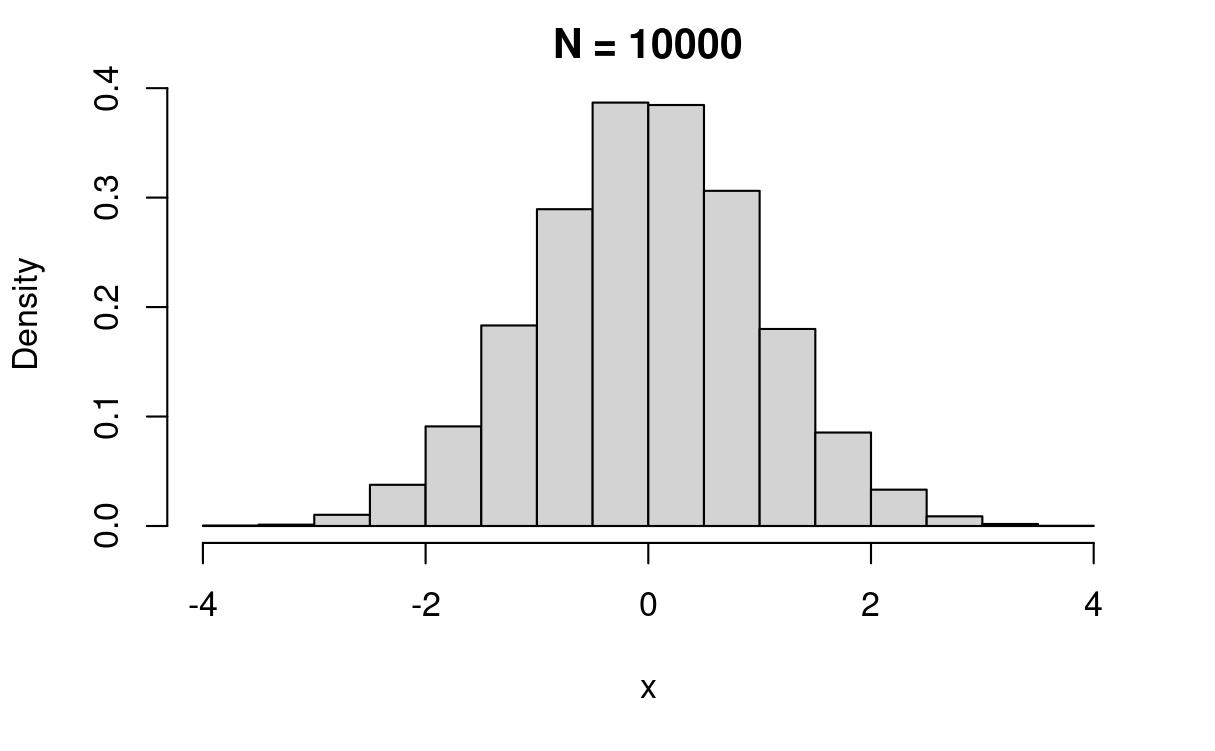
zbio7(100000)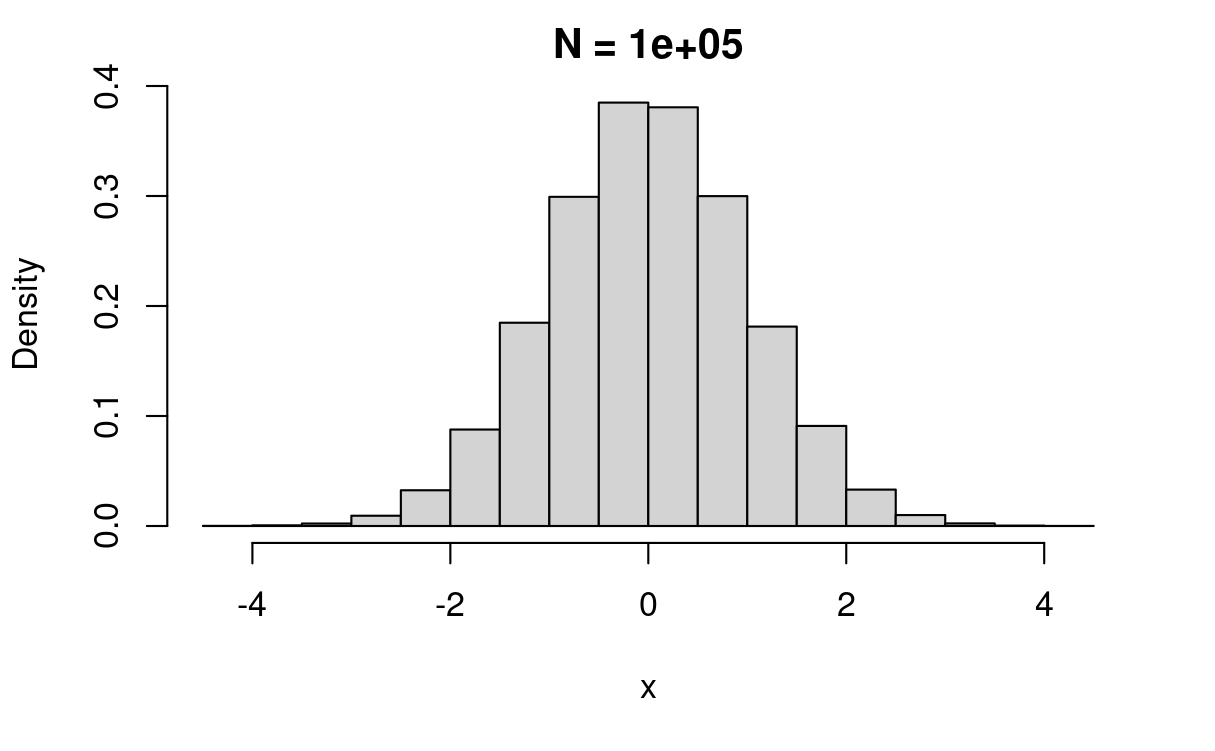
반복 수가 커질 수록 우리가 아는 정규분포 확률 함수의 모양에 가까워지는 것을 볼 수 있습니다.
즉, 확률 변수 X가 어떤 확률 분포를 따른다는 것은,
하나 하나의 개별 샘플은 그 확률 함수 정의역의 어떤 수든 나와도 이상하지 않지만 (정의역은 함수의 x값 범위입니다. 맨 위의 파란 선으로 그린 이름모를 확률 분포의 경우엔 무조건 양수만 나올 거라는, 그런 의미입니다),
그 하나 하나의 개별 샘플을 전부 모아두고 전체적으로 보면 결국 확률 함수의 그래프와 비슷한 모양이 나온다!
라는 것을 의미합니다. 다시 말해, 동일한 사건의 시행을 여러 번 했을 때, 그 시행들을 개별적으로 보지 않고 전체적으로 볼 때 우리가 아는 확률 분포의 모양을 볼 수 있을 것이다, 라는 뜻이예요. 딱 한 번의 개별 시행에서 기댓값과 전혀 동떨어진 쌩뚱맞은 값이 나왔다고 해서 그게 절대 절대 전혀 이상한 일은 아니고, 당연히 그럴 수 있는 일이니까 그걸로 '교수님 전 바보 돌문어 해삼 말미잘이예요' 할 필요가 없다는 의미입니다.
그래서 시뮬레이션은 의미를 갖습니다. 그리고 실험에서도 항상 '충분한 샘플의 크기 혹은 반복'을 강조하고, 논문에서도 실험 샘플 수를 항상 밝히는 이유도 여기에 있어요. 더불어, 실험 데이터를 생성할 때 요인이 아닌 컨디션을 최대한 동일하게 유지하려 하는지도 이런 부분에서 논의할 수 있습니다. 조건이 달라지는 순간, 확률 변수가 따르는 확률 분포도 달라질 수 있으니까요.
위의 정규분포 케이스로 부연 설명을 드리면 컨디션이 달라지면서 평균이나 분산 같은 파라미터가 달라질 수 있다는 뜻입니다. 서로 다른 실험 수행이 다른 확률 분포를 따른다면(i.e. 확률 함수의 모양이 다르다면), 그들은 다른 실험 데이터라고 하는 게 더 그럴싸 하고 그렇죠.
또한 나중에 논의할 '추정' 도 이런 아이디어를 차용합니다. 그러니, 이 시리즈 초반에 소개해 드렸던 말을 다시 한번 외쳐 보는 것으로 이번 포스트를 마치도록 할게요.
"확률은 '아님 말고' 다!"
+.
시뮬레이션에 관해서는, 유니폼 분포(Uniform distribution)와 변수 변환을 통해 진행하기도 합니다만,
수리 통계학적 내용이기에 이는 기회가 되면 부록으로 다뤄 보도록 하겠습니다.
관심이 있으신 분들께서는 구글에 "Change of variables" 혹은 그와 관련된 아티클들을 참고하셔도 좋겠습니다.
다음 시간부터는 정규 분포처럼 자주 사용되는 확률 함수 프리셋, 즉 확률 분포들을 소개해 드릴 텐데요,
우선 베르누이 시행(Bernoulli trials)과, 그로부터 더 이어나가 볼 수 있는 여러 분포들을 살펴 보는 내용을 준비해 오겠습니다.
'Z-bio stat > Z-기초통계학' 카테고리의 다른 글
| [Z-bio Stat] 9. Poisson Process: Exponential, Gamma, Beta Distribution (0) | 2023.01.24 |
|---|---|
| [Z-bio Stat] 8. Bernoulli Trial: Binomial, Geometric, Hypergeometric, Negative Binomial Distribution (0) | 2023.01.10 |
| [Z-bio Stat] 6. 데이터와 차원의 표현: 정보의 압축 (0) | 2022.12.29 |
| [Z-bio Stat] 5. 선형대수 표시법: Matrix를 왜 쓰는가? (0) | 2022.12.22 |
| [Z-Bio Stat] 4. 확률 함수 : cmf / cdf / pmf / pdf (0) | 2022.11.28 |



