
- 확률(Probability)의 재정의
- 통계와 통계량(Statistics)
- 샘플링(Sampling)과 확률 변수(Random Variable)
- 확률 함수: cmf / cdf / pmf / pdf
- 선형대수 표시법: Matrix를 왜 쓰는가?
- 데이터와 차원의 표현: 정보의 압축
- 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset)이다
- Bernoulli Trial: Binomial, Geometric, Hypergeometric, Negative binomial distribution
- Poisson Process: Exponential, Gamma, Beta distribution
- 추정(Inference): 귀무가설과 대립가설, 유의 수준과 p-value, 신뢰구간(CI)
- 추정(Inference) (2): Pivotal quantity, Student-t, Chi-square, F test and ANOVA table
- Experiment prediction: 회귀분석(Regression Analysis)의 가정(assumptions)과 아이디어
- Appendix
< 이번 포스트는 스마트폰 보다 태블릿, PC 등에서 보시기 편하게 작성되었습니다. >
들어가기 전에,
일반적으로 저희가 이미 알고 있고, 익숙한 확률 분포들, 예를 들자면 정규 분포(Normal distribution) 혹은 이항분포(Binomial distribution)와 같은 것들을 포함해서, 과학에서는 수능 문제와 달리 그들 사이에 중요도의 우위는 없다고 말씀 드리고 싶습니다.
예를 들어, 최근 핫한 연구 분야 중 하나인 single-cell sequencing 데이터의 처리에 사용되는 SCTransformation이라는 과정(메서드)이 있는데, 이 때 NB 분포(제목에 있는, Negative Binomial)를 회귀 모델로 사용합니다.
이 말이 무슨 말인지 단번에 이해하시는 분이시라면 이 포스트를 볼 필요는 없을 것 같으니 대충 그냥 확률 분포가 바이오에서 생각보다 가깝게 쓰인다는 거고, 이해할 필요는 없습니다 (실제로 실험 데이터의 분석을 진행하시는 분들 중에도 SCT를 언제 쓰는지는 알지만 그게 뭔지 모르시는 분들도 많으실 거예요).
요는, 언제 어디서 무얼 마주칠지 모르니 일단 "이런 상황에서 쓰는 분포 이름이 이런거였었지" 정도라도 알고 가셨으면 좋겠다는 거예요.
그리고 그 분포들 사이의 연결 고리를 캐치하시는 게 이해의 핵심이리라 생각합니다. 그러려고 분포 관련한 내용을 두 편으로 나눴거든요!
1. 베르누이 시행 (Bernoulli Trials)
이번 포스트에서는 베르누이 시행에서 출발하는 분포들을 소개해드릴 예정입니다.
바이노미얼(Binomial ; 이항 분포), 지오메트릭(Geometric ; 기하 분포), 하이퍼 지오메트릭(Hypergeometric ; 초기하 분포), 엔비 분포(Negative Binomial ; 음이항 분포)의 의미와 함수 식, 그리고 그들 간 어떤 관계가 있는지까지 간단히 보여 드릴게요.
이들의 '기본 단위' 인 베르누이 시행, '베르누이' 라는 이름만 보면 무슨 유체역학이 떠오르고 어지럽지만 통계에서의 베르누이는 멀리 할 필요가 없는 친구입니다.
베르누이 시행은 간단히 "성공, 실패" 두 가지 결과가 있는 시행을 이야기합니다.
이게 말이 성공과 실패지, 사실 "내가 관심있는 사건이 일어났다 / 일어나지 않았다" 로 해석할 수 있는 모든 것은 이걸로 해석될 수 있습니다. 예를 들어,
- 자라가 토끼와 가위바위보를 딱 한 번 한다 : 자라가 이기면 T, 지면 F .
- 동전을 딱 한 번 던진다 : 그림 면이면 T, 숫자 면이면 F .
- 셀에 약을 쳤을 때, 각각의 셀에 예상되는 반응이 있으면 T, 없으면 F .
등 생각보다 많은 것들을 베르누이 시행으로 이해할 수 있습니다.
위의 예시들에서 강조드린 걸 보고 눈치 채셨을 것 같은데, 베르누이 시행은 딱 한번의 행위를 말합니다.
이런 베르누이 시행의 확률을 결정하는 것, 즉 베르누이 시행의 파라미터는 어떤 것이 있을까요?
바로 사건이 일어날 확률 그 자체예요. 간단히 생각해서, 그게 없으면 우리가 뭘 유도해 낼 수 없으니까요.
그럼 언뜻 생각해서 베르누이 시행의 확률 함수를
$$ f_X(x)=p $$
라고 잘못 생각할 수 있지만, 확률 함수의 합은 1이다! 라는 것을 기억해 봐요.
베르누이 시행의 sample space는 "성공(T)", "실패(F)" 두 가지 입니다. 파라미터로 쓴 성공 확률을 p라고 했으니, 실패할 확률은 1-p가 될 거예요.
시행이 성공할 확률이 p, 실패할 확률이 1-p . 이런 함숫값이 나오도록 베르누이 시행의 확률 함수를 쓰면 아래와 같습니다 :
$$ X \sim Bern(p) \Rightarrow f_X(x)=p^x(1-p)^{1-x},\quad x=0,\;1 $$
관심있는 사건이 일어났을 때의 x를 1, 일어나지 않았을 때 x를 0으로 생각한 것입니다. 이런 식으로, 통계학에서는 확률을 수학으로 다루기 때문에, 글자로 표현된 실험을 숫자로 바꿔주는 아이디어가 중요해요.
논문이나 다른 곳에서 통계를 접하실 때, 변수(X)가 어떤 의미를 갖는지 명확하게 파악하시면 아마 좋은 일이 일어날 거예요.
아무튼, 이런 베르누이 시행에서도 평균과 분산, MGF를 계산해 볼 수 있습니다. 심심하면 앞에서 소개해 드렸던 걸로 직접 계산해보셔도 좋아요. 별로 오래 걸리지 않습니다 (분산은... 뺄게요 ! ) :
$$ E(X)=p $$
$$ M_X(t)=[pe^t\;+\;(1-p)] $$
여담이지만, 제가 계속 성공을 T, 실패를 F라고 쓰는데, 개인적인 추측이지만 일반적으로 이런 기호를 쓰는 건 코딩 때문이 아닐까 해요.
파이썬과 같은 코딩에서 TRUE와 FALSE의 형태로 결과를 return하는 식을 'Boolean expression, 불 표현식' 이라고 하는데, 제가 일단 T와 F로 쓰는 게 편하니 앞으로는 그렇게 쓰도록 할게요.
아래에서 소개해 드릴 확률 함수들은 모두 이 베르누이 트라이얼을 단위로 합니다.
시행을 한 번, 두 번 이렇게 셀 수 있다는 거예요.
즉, 이 포스트에 있는 확률 분포들은 전부 이산(discrete) 확률 분포 입니다.
2. 이항 분포 (Binomial Distribution)
분명히 어디선가 배우셨을 유명한 분포입니다.
아시다시피 바이노미얼은 "성공 확률이 p인 어떤 일을 n번 반복했을 때, 성공 횟수의 확률 분포(=함수)" 를 의미하는데,
즉 바이노미얼을 따르는 확률 변수 X=3 이라면, n번 시행 중 3번 성공할 확률이 바로 함숫값이 돼요.
이 포스트에서 제가 소개해 드리고 싶은 바이노미얼의 의미는 베르누이 시행의 합 입니다.
아니 그게 그 말 아녀? 함수 식과 평균, 분산을 먼저 짚고 저게 무슨 말인지 살펴 볼게요.
$$ X \sim Bin(n, p) \Rightarrow f_X(x) = \begin{pmatrix} n \\ x \end{pmatrix} p^x (1-p)^{n-x},\quad x \in \{0,1,2, \cdots n \} $$
$$ E(X)=np, \quad Var(X)=np(1-p) $$
$$ M_X(t)=\{ pe^t + (1-p) \}^n $$
참고로, \( \begin{pmatrix} n \\ x \end{pmatrix} \) 는 nCx (조합, "n combination x") 을 뜻합니다.
바이노미얼이 어떤 의미인지 살짝 짚어 보기 위해, 상황을 하나 가정해 볼게요.
이 시대의 진정한 천재 과학자, 용궁대학교 이자라 교수가 "어떤 병이든 낫게 해주는 약" 을 만들고 있어요.
강력한 후보 물질 "JONJAL-xLzL"을 발견한 자라 교수는, 떼돈을 벌기 위해 회사를 만들고 임상 실험을 준비합니다.
다음 날이면 죽는 병을 가진 두 개의 배지 A와 B를 준비하고, A에만 "JONJAL-xLzL"을 처리하네요. 각각의 콜로니에는 10만개의 셀이 있다고 가정해볼게요.
아침이 밝았습니다. 설레는 마음을 품고 자라 교수는 배지 B를 들여다 봐요.
예상대로 배지 B의 셀들은 다 죽었습니다. 안타깝지만 그들의 희생이 헛되지 않길 바라며, 자라 교수는 이번에는 배지 A의 셀들을 하나씩 살펴 봅니다.
첫 번째 셀, 살았습니다.
두 번째 셀, 살았습니다.
세 번째 셀, 죽었습니다.
네 번째 셀, 살았습니다.
...
9만 9천 9백 9십 9번째 셀, 죽었습니다.
10만 번째 셀, 살았습니다.
자, 각각의 셀은 살거나, 죽거나 두 가지의 결과만 가집니다. 즉, 시행의 샘플을 각각의 셀 이라고 보면 이 실험 데이터는 베르누이 시행의 데이터예요. 그러한 베르누이 시행을 10만번 진행한 거라고 이야기할 수 있을 겁니다.
조금만 더 가보겠습니다. 첫번째 셀이 살았다면 C1=1, 죽었다면 C1=0 으로 표시해 봅니다. 그럼 위 실험 데이터는,
C1=1
C2=1
C3=0
C4=1
...
Ci=1 or 0
...
C{10+5e -1}=0
C{10+5e}=1
로 쓸 수 있을 거예요.
총 10만개의 셀 중에 살아남은 셀이 k개 라고 해 볼게요. 그럼 이 실험에서 평균은,
$$ \frac{C_1+C_2+C_3+ \cdots +C_{99999} + C_{100000} }{100000} = \frac{k}{10^5} $$
같은 상황을 다른 각도에서 살펴 보겠습니다. 이번엔 각 셀을 각각의 샘플로 보지 않고, 10만 개의 셀을 통채로 하나의 샘플로 보겠습니다. 그럼 이 때 이 실험은, n=10^5 인 바이노미얼을 따른다고 이해할 수 있겠습니다.
살아 남은 셀이 k개 였습니다. 그럼 우리는 성공 확률을 \( \frac{k}{10^5} \) 라고 추측할 수 있을 거예요.
그런데 이 추정값은 앞에서 본 베르누이 샘플의 평균입니다.
그래서, 무슨 말을 하고 싶은 건데?
실제로 우리가 연구 상황에서 확률 분포를 만나게 되는 상황은 수능 문제와 달리 "이 샘플이 이 분포를 따른다" 라고 주어지지 않습니다. 실험 조건과 데이터를 보고 "이 데이터가 이 분포를 따를 것 같은데?" 와 같이 생각해 낼 수 있어야 해요.
바이노미얼을 만나는 상황은 위와 같은 경우가 많습니다. 베르누이 시행을 독립/동일한 조건으로(iid) 반복하는 상황에서, 그들의 '평균' 자체를 하나의 '확률 변수'로 볼 때 그 평균이 바이노미얼을 따른다고 이해할 수 있는 겁니다.
같은 상황을 MGF를 통해 나타내면 이렇습니다.
들어가기 전에, X와 Y가 iid 샘플일 때,
$$ M_X(t)=E(e^{tX}) \\ M_Y(t)=E(e^{tY})$$
$$ \Rightarrow M_{X+Y}(t)=E(e^{(X+Y)t})=E(e^{tX}e^{tY})=M_X(t) \times M_Y(t) $$
즉, X와 Y의 합의 MGF는 X의 MGF와 Y의 MGF의 곱과 같습니다.
\( X \sim Bern(p) \) 일 때, \( M_X(t) = (pe^t + 1 - p) \) 였습니다. 그럼, 같은 베르누이 시행에서 나온 iid 샘플들, 즉
\(X_1,X_2, ... , X_n \sim^{iid} Bern(p) \) 일 때,
$$ \begin{aligned} Y=\sum_{i=1}^n X_i \Rightarrow M_Y(t) &= \prod_{i=1}^n M_X(t) \\ &= \prod_{i=1}^n (pe^t +1-p) \\ &= (pe^t +1-p)^n \end{aligned} $$
이 마지막 식이 바이노미얼의 MGF이기 때문에,
$$ Y \sim Bin(n, p) $$
라고 할 수 있습니다. MGF는 분포의 지문이니까요!
네, 당연히 이런 방식의 유도는 기초 통계학의 범위를 벗어나는 내용입니다.
제가 웻랩에는 문외한이라 이 정도까지의 통계 수준을 요구하는지는 모르겠지만 (아마 이런 수학적인 내용까지는 필요없지 싶습니다), 드라이랩 내지 모이스처랩(이라고 흔히 부르는 방) 수준에서 데이터의 분포를 유도해 낼 일이 있으시다면 이런 흐름은 전혀 깊은 수준이 아닐 겁니다. MGF라는 것 자체보다도, 이렇게 수학적으로 분포간의 연결 고리를 만들어 두는 게 정말 정말 유용한 아이디어가 될 거예요.
3. 기하 분포 (Geometric distribution)
어휴 머리를 엄청 쓴 것 같은데 아직도 두 개 밖에 안봤어?
네, 저 "단위로서의 베르누이 트라이얼" 이 어떤 의미인지 캐치하셨다면 여기부턴 다 비슷비슷하게 돌아갑니다.
바이노미얼은 그들 중 처음이라 되게 길게 보여드린 거 였구요.
한국어 '기하 분포' 는 예상하시듯 영문 'Geometric' 을 번역한 건데, 오역 수준의 번역입니다.
여기서 Geometric은 '도형, 기하' 라기보다는 '기하 급수적인, 지수적인' 의 의미로 보시면 좋을 것 같아요.
저는...학부 전공 필수 강의들이 전부 영강이었던 탓에 한국어 분포 이름은 실시간으로 검색해서 병기하고 있었는데,
'기하 분포' 는 도저히 입에 붙질 않아서 그냥 '지오메트릭' 이라고 부르겠습니다.
아마 다음 포스트에도 똑같은 말씀을 드릴 수 있을 것 같습니다 :
먼저 '시행 횟수'에 관한 확률 분포를 봤다면, 그 다음에 따라오는 것은 반드시 '1회 T(성공) 까지 걸린 시간 (Waiting time)' 입니다.
지오메트릭은 이 "성공까지 걸린 시행 횟수" 의 확률을 나타낸 것입니다.
즉, 지오메트릭을 따르는 확률 변수 X=3의 함숫값은 세 번째 시행에서 처음으로 성공이 뜰 확률을 의미합니다.
"처음으로 성공" 이라는 제약을 걸어 뒀으니, 지오메트릭의 파라미터는 성공 확률 p 하나로 충분합니다.
$$ X \sim Geo(p) \Rightarrow f_X(x)=p(1-p)^{x-1}, \quad x \in \{ 1, 2, \cdots \} $$
$$ E(X) = \frac{1}{p}, \quad Var(X) = \frac{1-p}{p^2} $$
$$ M_X(t) = \frac{pe^t}{1-(1-p)e^t}, \quad where \;\; t<-ln(1-p) $$
평균이고 분산이고 MGF고 누가 물어 보면 그 때 계산 때려 보시면 됩니다. 무한 등비 급수를 이용하면 되는, 어렵지 않은 계산이예요.
대신 pmf의 의미만 간단히 살펴 보도록 하겠습니다.
\( f_X(x) \) 라는 것은, 딱 정해진 숫자인 "x" 번째 시행에서 처음으로 성공이 뜰 확률을 이야기해요.
다시 말해서, 첫 번째 시행부터 "x-1" 번째 시행까지는 모조리 실패가 뜨고, 마지막 "x" 번째 시행에서는 성공이 떠야 합니다.
$$ f_X(x)=(1-p) \times (1-p) \times \cdots \times (1-p) \times p $$
3-1. Memoryless Property
이름부터 쌩뚱맞게 생긴 이 property는 비단 지오메트릭에서만 쓰는 말은 아니고, waiting time에 관련된 다른 확률 분포들에도 적용해 볼 수 있는 개념입니다. 그냥 "이런 상황을 말하는 거구나" 정도로 알아 두시면, 살면서 한 번 쯤은 마주치시게 될 거예요.
지오메트릭 상황을 하나 생각해 보겠습니다.
$$ X \sim Geo(p) \Rightarrow P(X=5)=p(1-p)^5 $$
이걸 그림으로 보면 이런 상황일 겁니다 :

자라가 앞으로 다섯 번의 시행을 할 건데, 다섯 번째에서 성공할 확률 !
...을 나름대로 나타낸 그림이랍시고 그린 겁니다.
자, 자라가 여기서 두 번을 시도했고, 두 번 다 실패했습니다.

그럼 이제 처음 시점에서 다섯 번째에 성공할 확률은, 현재 시점에서 세 번째에 성공할 확률과 같아지게 됩니다.
너무 당연한 소리 아니냐? 네, 당연한 소리 하는 것 맞습니다.
이게 바로 Memoryless property 예요. 말 그대로 과거가 된 일은 생각하지 않겠다는 겁니다.
그리고 이걸 수학적으로 쓰면 아래와 같아요 :
총 다섯 번의 시행 중, 처음 두 번을 실패하는 사건을 A라고 할게요. 그럼,
$$ P(X=5 | A) = P (X=3) $$
저 vertical bar, 막대기는 저희가 교복입고 돌아다니던 시절에 배웠던 조건부 확률이라는 건데,
간단히 위 식의 우변은 "다섯 번째 시행에서 성공할 확률, 근데 이제 처음 두 번의 시행에서 실패했을 때." 처럼 읽으시면 됩니다.
갑자기 불편한 토끼가 딴지를 겁니다.
"난 두 번째 성공이 언제 뜰지 그 확률 분포가 궁금한데? 근데 지오메트릭은 첫 성공이 뜰 확률만 다루면, 어디서 이걸 알아봐야 하냐?"
그런 토끼를 위해 준비했습니다. 바로 다음으로 볼 확률 분포는, 지오메트릭에 파라미터를 하나 추가한, 지오메트릭의 DLC(확장팩) 입니다.
4. 음이항 분포 (Negative Binomial Distribution)
아, 계획대로면 NB가 이 포스트 마지막에 나와야 하는데. 설계를 잘못 했습니다 젠장.
NB의 X=x에서의 확률 함숫값은 위에서 언급 드렸듯, 성공 확률이 p인 시행을 x번 했을 때 정확히 r번째 성공이 뜰 확률을 의미합니다.
$$ X \sim NB(r, p) \Rightarrow f_X(x)= \begin{pmatrix} x-1 \\ r-1 \end{pmatrix} p^r(1-p)^{x-r} , \quad x \in \{r, r+1, \cdots \}$$
$$ E(X)= \frac{r}{p}, \quad Var(X)=\frac{r(1-p)}{p^2}$$
$$ M_X(t) = \left( \frac{pe^t}{1-(1-p)e^t} \right)^r $$
NB의 MGF는 지오메트릭 MGF의 r제곱 입니다(4-1을 봐 주세요!).
※E(X)가 알고 계신 것과 다르실 수 있는데 곧 설명 드리겠습니다.
pmf의 유도는 그림 하나로 퉁치겠습니다.
절대 랩실 퇴근하고 3일째 수식 치느라 피곤해서 그런 것 아니예요. 아무튼 아님.
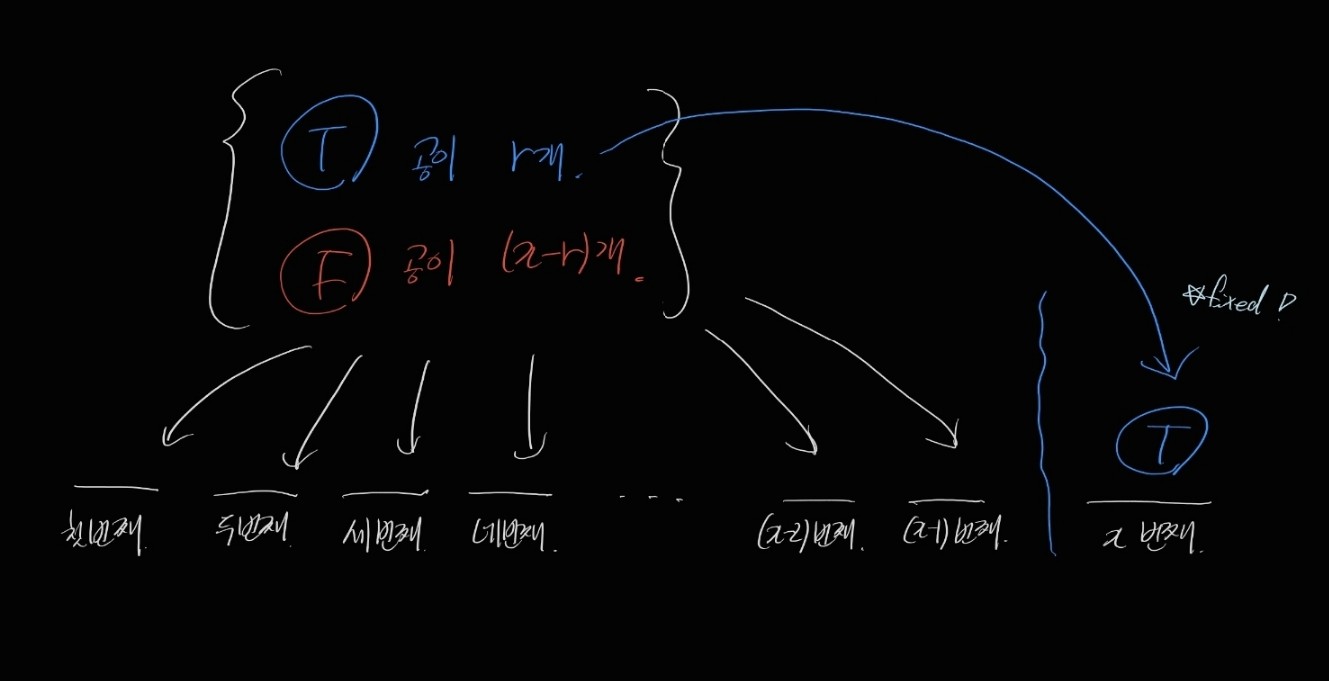
총 x개의 자리에 r개의 파란 공(성공) 과 (x-r)개의 빨간 공(실패) 를 배열할건데, x번째 자리에는 반드시 파란 공이 와야만 합니다.
파란 공이 선택될 확률이 매 번 p고, 빨간 공이 선택될 확률이 매 번 (1-p)라면,
원하는 배열이 나올 확률은 \( p^r (1-p)^{x-r} \) 일 겁니다.
여기에, 가능한 배열의 가짓수를 곱해줄게요.
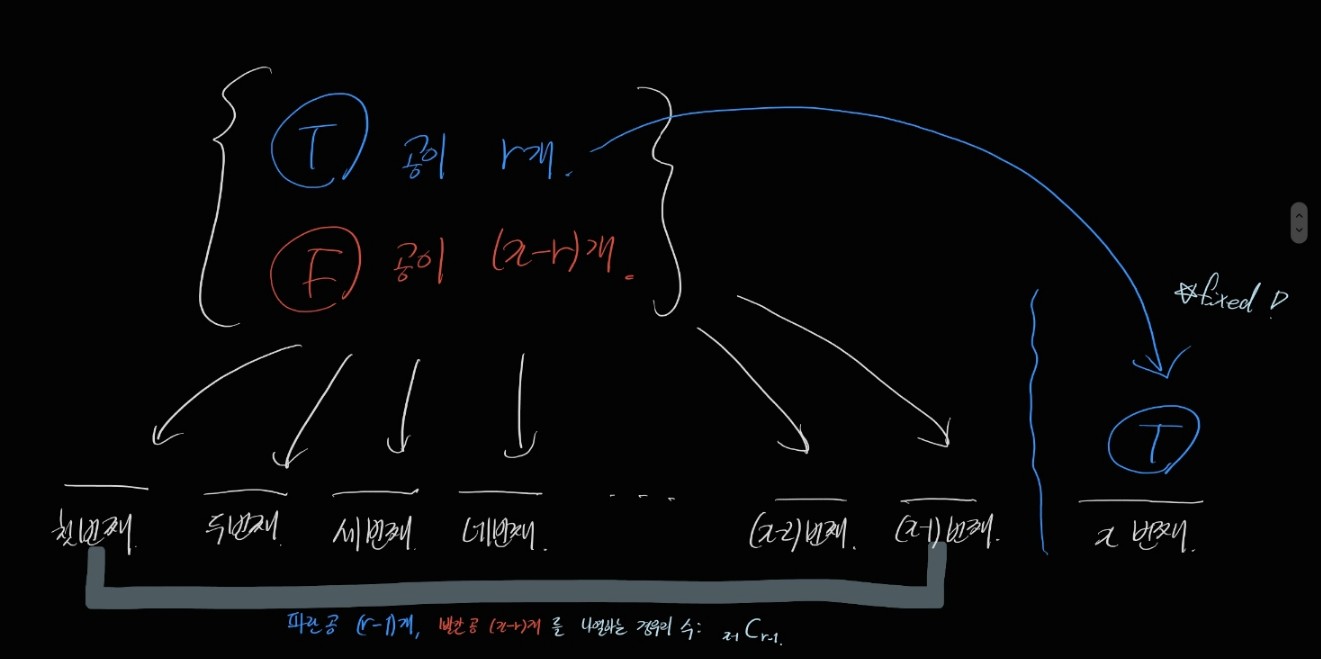
이렇게 NB의 pmf를 유도해 낼 수 있습니다.
그런데 아마 위키백과에 "Negative binomial distribution"을 검색해서 나오는 기댓값은, 위에서 제가 설명드렸던 것과는 다를 겁니다.
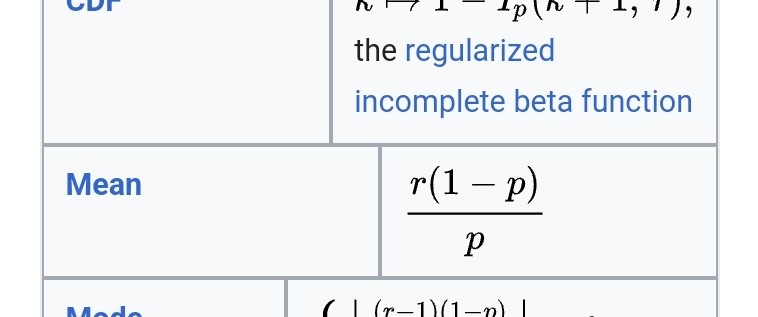
이게 어떻게 된 일일까요?
그건 위키와 제가 지오메트릭을 보는 관점이 달랐기 때문입니다. 즉, 위키가 말하는 r과 제가 말하는 r이 다른 숫자예요.
그리고, 둘 다 틀린 말은 아닙니다.
4-1. 하나만 하지 좀 왜 이걸로 썼다 저걸로 썼다
위키 이것들은 지오메트릭 평균은 두 케이스로 나눠 썼으면서 NB는 왜 저렇게 써가지고 사람 피곤하게 만드는 걸까요.
앞서 말씀드린 것처럼, 위키 식과 제 식이 다른 것이 아님을 보여 드리기 위해 일단 NB의 기댓값을 그림으로 유도해 보겠습니다.
\( X \sim NB(r, p)\) 일 때 \(P(X=x)\) 를 이렇게 그려 볼게요 :

그리고 이걸 파란 공을 기준으로 모조리 잘라 버리겠습니다.

그러면 각각의 잘린 마디들, 그러니까 노란색, 하늘색, 빨간색, 초록색, ... 들은 각각 별개의 지오매트릭을 따른다고 볼 수 있습니다.
즉 NB 상황을, 노란색 지오메트릭 -> 끝나면 하늘색 지오메트릭이 새로 시작 -> 끝나면 빨간색 지오메트릭이 새로 시작 -> ... 으로 읽은 겁니다. 같은 상황인 게 받아 들여지시나요?

자, 이걸로 NB의 expectation을 구해 볼게요.
$$ X \sim NB(r, p), \quad X_i \sim^{iid} Geo(p) $$
(그림 그릴 때 아무 생각 없이 NB와 Geo의 확률 변수를 모두 X로 써서 헷갈리시겠지만... 양해 부탁 드리겠습니다. 곧 수정하겠습니다.)
$$ \begin{aligned} E(X) &= E(X_1 + X_2 + \cdots + X_{r-1} + X_r) \\ &= E(X_1) + E(X_2) + \cdots + E(X_{r-1}) + E(X_r) \quad (by\;\; "Linearity\;\;of\;\;Expectation) \\ &= \frac{1}{p} + \frac{1}{p} + \cdots + \frac{1}{p} + \frac{1}{p} \\ &= \frac{r}{p} \end{aligned} $$
그런데 위키에서 소개된 NB의 mean에는 (1-p)가 곱해져 있습니다. 이게 뭘까요?
일단 NB의 평균은 지오메트릭 평균의 합으로 구한다, 라는 걸 알았으니 위키에서 지오메트릭 평균을 찾아 볼게요.

어라, pmf가 두 개네요?
주목할 부분은 위의 "support" 부분인데, 서포트는 "함수 식을 만족시키는 범위", 즉 정의역이라고 생각하시면 됩니다.
그러니까, 사진의 k(제가 소개드린 지오메트릭 식에서는 x)의 범위를 다르게 잡은 겁니다. 그래서 지오메트릭의 평균도 다르게 나온 거예요.
사족으로 부연 설명 드리자면, 왼쪽 지오메트릭은 제가 본 것처럼 "k번째 시행에서 처음 성공"할 확률을, 오른쪽 지오메트릭은 "k번 실패 후 다음 시행에서 처음 성공"할 확률을 쓴 함수입니다.
아무튼 오른쪽 지오메트릭의 평균 식 중 분자에 1-p가 붙어 있어서, 위키의 NB 분포 식에도 1-p가 붙게 되었다... 라는 경위입니다.
어휴 NB 문서에도 두 가지로 나눠서 썼으면 좋았을텐데.
네, 해외 지식인(?)에도 이 질문이 있어서, 혹시나 헷갈리시는 분들 계실 까봐 길게 적어 보았습니다. 그냥 NB가 이렇게 생겼구나 하면 되세요.
5. 초기하 분포 (Hypergeometric distribution)
비슷한 것 끼리 묶는답시고 처음 이 프로젝트를 계획했던 것보다 포스트를 더 쪼개긴 했는데, 그래도 한 포스트에서 단번에 소화하기엔 꽤나 부담스러울 수도 있겠다는 생각이 드네요.
초기하 분포, 이름만 들으면 좀 어렵고 대단할 것 같지만 사실은 그냥 경우의 수 문제입니다.
상자에 A개의 성공(파란 공), B개의 실패(빨간 공)가 들어 있다고 가정해 보겠습니다.

여기서 n개의 공을 뽑겠습니다. 초기하 분포는 "뽑은 n개의 공 중 성공(파란 공)이 x번 뽑힐 확률" 을 나타냅니다.
와, 그냥 경우의 수 문제 같은걸요? 네 맞습니다, pmf도 그렇게 생겼어요.
$$ X \sim Hypergeo(n, A, B) \Rightarrow f_X(x)=\frac{\begin{pmatrix}A \\ x \end{pmatrix} \begin{pmatrix}B \\ n-x \end{pmatrix}}{ \begin{pmatrix} A+B \\ n \end{pmatrix} }, \quad where \quad n \leq A+B $$
그리고 x는 0과 n-B 중 큰 것과 ( i.e. max{0, n-B} ) n과 A 중 작은 것( i.e. min{n, A} ) 사이의 정수 입니다.
$$ E(X) = \frac{nA}{A+B}=np, \quad p=\frac{A}{A+B} $$
이 p는 성공 확률입니다. 분산과 MGF는 생략.
자, 베르누이 트라이얼에서 나온 확률 분포들의 함수 식은 알겠어. 근데 얘네들이 어떻게 생겼는지 궁금한데? 이 자라놈이 안그려주냐?
언젠가 말씀드렸던 것처럼, 확률 분포의 모양을 결정하는 건 "파라미터" 입니다. 그리고 정규 분포가 아니면, 파라미터에 어떤 수를 넣느냐에 따라 모양이 많이 크게 바뀔 수 있어요.
물론, 구글 검색창에다가 병기해드린 영어 분포 이름으로 이미지 검색을 해보시면 정말 좋은 자료들이 많이 있습니다. 그걸 보시는 것 만으로도 충분해요.
하지만, 내가 오랫동안 확률 분포를 쓸 것 같다! 하시는 분들이라면 파라미터에 따라서 분포가 어떻게 움직이는지, 감각을 어느 정도 갖고 계시는 게 좋을 것 같습니다. 그래서, 직접 확률 함수를 그려 보시는 방법도 추천드려요.
https://www.desmos.com/calculator?lang=ko
Desmos | 그래핑 계산기
www.desmos.com
Desmos는 제가 두 번째 수능을 볼 때부터 자주 애용해온, 그래프를 그려주는 사이트 입니다. 링크를 타고 들어 가셔서, 함수 식 입력 칸에다가 아래 수식을 입력하시면 함수 그래프를 만져 보실 수 있을 거예요.
아래 수식에서 <이렇게> 표시한 부분은 파라미터가 들어가는 자리니까, 그 자리에 여러가지 숫자를 넣어 보시면서 그래프가 어떻게 움직이는지 보시면 좋겠습니다.
물론 엄밀하게는 얘들이 다 연속 확률 함수는 아니지만, 대충 모양을 보고 싶은 거니까 그냥 연속 함수로 그려 버릴게요.
Bin (끝의 중괄호는 Desmos에서 함수 정의역을 지정해주는 문법입니다)
$$ y=\frac{<n>!}{(<n>-x)!x!} <p>^x(1-<p>)^{<n>-x} \{x \geq 0 \} $$
Geo
$$ y=<p> (1- <p>)^{x-1} \{ x \geq 0 \} $$
NB
$$ y=\frac{(x-1)!}{(<r> -1)!(x- <r>)!} <p>^{<r>} (1- <p>)^{x- <r>} \{x \geq <r> \} $$
HG (서포트는 적당히 넣어 주시면 됩니다)
$$ y= \frac{ <A>! }{ x! (<A> -x)!} \times \frac{<B>!}{(<n> -x)!(<B> - <n> +x)!} \div \frac{(<A>+<B>)!}{<n>! (<A>+<B>-<n>)!} $$
다음 포스트에는 포아송 프로세스(Poisson process)의 개념과, 그로부터 출발하는 확률 분포에 관한 내용을 준비해 보겠습니다.
사실 이번 포스트의 확률 분포와 크게 다르지 않아요 !
'Z-bio stat > Z-기초통계학' 카테고리의 다른 글
| [Z-bio Stat] 9. Poisson Process: Exponential, Gamma, Beta Distribution (0) | 2023.01.24 |
|---|---|
| [Z-bio Stat] 7. 정규분포로 보는 분포(Distribution)의 의미: 분포는 프리셋(preset) 이다 (0) | 2023.01.01 |
| [Z-bio Stat] 6. 데이터와 차원의 표현: 정보의 압축 (0) | 2022.12.29 |
| [Z-bio Stat] 5. 선형대수 표시법: Matrix를 왜 쓰는가? (0) | 2022.12.22 |
| [Z-Bio Stat] 4. 확률 함수 : cmf / cdf / pmf / pdf (0) | 2022.11.28 |



